※ 본 문서는 PC 환경에 최적화되어있습니다.
1 사전 Setup
실습에 들어가기 전 과거 TA가 제작한 다른 실습지를 참고하면 도움이 많이 되므로 참고.
1.1 Python Setup
아래의 명령은 rgee 패키지 설정을 완료한 사람에 한함.
1.2 Packages
Code
# 모델링 및 데이터 처리
library(tidyverse)
library(tidymodels)
library(data.table)
# 공간자료 다루는 용도
library(sf)
library(stars)
library(raster)
library(terra)
# 공간자료 가시화
library(tmap)
library(tmaptools)
tmap_options(check.and.fix = TRUE)
library(leafem)
library(OpenStreetMap)
# 웹 크롤링 관련
library(RSelenium)
library(rvest)
library(xml2)
# R-Python 연결고리
library(reticulate)
# 원격탐사 데이터 수집 및 처리
library(rgee)
# 자료 병렬처리
library(doParallel)
# 마크다운 aes
library(reactable)2 Spatial Data in R Crash Course
2.1 Some Prerequisites
2.1.1 경로 개념 - 절대경로와 상대경로
엑셀과 같은 외부 데이터를 불러오기에 앞서, 파일 경로에 대한 이해가 필요하기 때문에 마련한 부분이다. 익혀두면 R 뿐만이 아니라 다른 프로그래밍을 할 때에도 도움이 되는 부분이라 생각된다.
디렉터리
본격적으로 경로에 관해 알아보기 앞서 디렉터리에 관한 개념을 짚고 넘어가고자 한다. 후술할 경로 또한 이 디렉터리의 위치에 대한 경로이기 때문이다.
파일 분류를 위해 붙이는 이름공간이다. 보통 MS-DOS, UNIX와 같은 CLI 환경에서는 디렉터리라고 하고, Windows, OS X와 같은 GUI 환경에서는 폴더라고 한다. 이 둘은 거의 똑같은 개념이라고 볼 수 있으며, 파일은 공, 디렉터리는 공을 담는 천 주머니에 비유하면 된다.
홈 디렉터리
Windows 운영체제보다 Unix 계열의 운영체제에서 많이 쓰이는 개념이다. 다중 사용자의 사용을 매끄럽게 지원하는 Linux 운영체제를 예시로 들면, 각 사용자의 계정 디렉터리를 의미한다.

Windows에서도 터미널에 환경변수 $HOME을 침으로써 확인할 수 있다.
아래의 예시는 R 환경의 홈 디렉터리 값을 확인하는 코드이다. Windows 내장 터미널에 $home을 쳐보기를 권장.
루트 디렉터리
루트 디렉터리(root directory)는 주로 유닉스와 유닉스-계열 운영 체제(Linux 등)에서 사용되는 개념인데, 컴퓨터 파일 시스템에서 계층 구조의 첫번째 또는 최상위 디렉토리를 가리킨다. 트리 구조의 줄기에 비유할 수 있는데, 모든 가지들이 뻗어 나오는 시작점의 역할을 한다.

이를테면, 보편적인 하드 디스크와 운영 체제를 갖춘 환경에서 C 드라이브의 루트 디렉토리는 C:\이다.
작업 디렉터리
작업 디렉터리(working directory)란 컴퓨터 운영체제 혹은 프로그래밍에서 모든 입력 작업과 출력 작업이 이루어지는 기본 위치이다.
즉, R의 변수를 파일 데이터로부터 읽어오거나, 변수에 저장된 데이터를 다른 형식의 파일(.txt, .csv, .shp 등)로 저장하고자 읽기 및 쓰기와 관련한 함수를 실행하였을 때, 함수의 인자에 경로에 관한 것을 넣지 않는다면 현재 작업경로에서 읽어올 파일을 찾거나 현재 작업경로에 파일을 만든다.
R에서 현재 작업 디렉터리를 반환하는 함수는 다음과 같다.
절대경로
’절대경로(Absolute Path)’는 자신이 원하는 경로를 Root 디렉터리부터 모두 적은 것을 의미한다. Linux 계열 운영체제의 Shell(Bash, csh, zsh 등)이나 Windows 운영체제의 Powershell에서 pwd를, Windows 운영체제의 명령 프롬프트(Command Prompt) cd를 입력하여 실행함으로써 현재 작업공간의 경로를 절대경로로 조회가 가능하다.
현재 문서를 작성하는 작업공간(working directory)의 절대경로를 예로 들자면,
/c/Users/dydgn/OneDrive - SNU/2023-1/lecture/SA3/TA/rgee 현재 작업공간을 /c,(Windows 표현: C:\)라는 Root로부터의 절대경로로 표현한 것이다.
‘작업공간’ 혹은 ’작업 폴더’는 데이터를 불러오거나 외부로 저장하는 작업을 수행하는 기본 폴더이다. 쉽게 말해서 작업이 이루어지는 공간으로, 파일을 읽거나 저장할 때, 따로 경로를 지정하지 않으면 해당 폴더로 저장된다.
Shell 프로그램 외에도 R 내장 함수로도 조회가 가능하며 getwd()함수로 조회가 가능하다.
getwd() 함수의 반환 값으로 알 수 있는 현재 작업경로의 절대경로는 다음과 같다.
C:/Users/dydgn/OneDrive - SNU/2023-1/lecture/SA3/TA/rgee
상대경로
’상대 경로(Relative Path)’는 특정 경로를 기준으로 다른 경로는 표시하는 개념이다. 상대경로를 표시할 때는 ‘.’과 ‘..’을 함께 많이 사용하는데 ‘.’은 현재 경로(Current Directory)를 의미하고 ‘..’은 상위 경로(Parent Directory)를 의미한다.
예를 들어 현재 작업 공간을 상대경로로 다시 나타낸다면 다음과 같이 나타낼 수 있다.
.
간단하지요?
진짜인지 확인하기 위해 작업공간을 설정할 수 있는 setwd() 함수를 이용하여 확인해보자.
[1] "C:/Users/dydgn/OneDrive - SNU/2023-1/lecture/SA3/TA/rgee"절대경로에서 확인한 경로와 동일함을 알 수 있다.
참고로 ‘..’은 상위 경로를 탐색할 때 사용되고, 하위 경로를 탐색할 때에는 절대경로와 동일하게 원하는 파일이나 폴더를 명시하면 된다. ‘.’은 현재 경로를 명시적으로 나타낼 때 사용된다.
Code
[1] "data" "images" "rgee.qmd" "rgee.rmarkdown"[1] "data" "images" "rgee.qmd" "rgee.rmarkdown"Code
[1] "rgee" "rgee_distro" "rgee_distro.zip"Code
[1] "Datasets" "radar_rainfall" "raster" "shp" 상대경로의 장점은 프로젝트 파일을 다른 사람과 공유할 때, 보통 R 문서(확장자가 .R, .qmd)이 포함된 작업공간 폴더를 통째로 공유한다면 공유를 받은 사람이 작업 시 경로를 하나하나 해당 작업공간에 맞게 변경하지 않아도 되는 장점이 있다.
절대경로는 작업공간이 아닌 D 드라이브와 같은 자료 저장소에서 자료를 불러올 때 유용하다. 만약 저장소 파일을 상대경로로 지정한다면, 사용자의 PC 내에서 R 문서를 옮긴다면 오히려 파일 경로가 깨질 것이다.
다음 사진을 보면 이해가 빠를 것이다.

2.1.2 Encodings
문자 집합(Character Set)
컴퓨터는 모든 정보를 이진법이라는 숫자 체계로 인식한다. 인코딩은 우리가 읽을 수 있는 정보의 체계를 컴퓨터의 체계로 변환해주는 작업이다. 반대로 1과 0으로 구성된 정보를 우리가 원하는 정보로 변환하는 것을 디코딩이라고 한다.
이러한 인코딩과 디코딩을 하기 위해서 어떠한 규칙을 담은 암호표를 만들어야 한다. 그렇지 않으면 정보를 주고받는 과정에서 원하는 결과를 얻을 수 없기 때문이다. 문자 정보를 주고 받는 과정에서의 이러한 약속을 문자 집합(Character Set)이라고 한다.
문자 집합을 서로 맞춰주지 않으면 정보를 주고받는 과정에 문제가 생긴다. 이러한 문제를 얕게나마 짚고 넘어가고자 한다.
문자열 인코딩
Code
[1] "\xb0\xfc\xbeDZ\xb8"위 예시는 우리가 흔히 글자가 깨졌다고 하는 인코딩 오류의 결과이다.
cp949 인코딩이 기준으로 하는 문자 집합을 기준으로 하지 않고, Unicode 기준의 UTF-8 인코딩으로 읽어왔을 때 볼 수 있다.
특히 이러한 현상은 tidyverse - readr 패키지의 read_delim() 계열 함수(read_csv() 등)를 사용하여 자료를 읽어올 때 쉽게 볼 수 있다. 모든 readr 함수는 입력받는 값의 인코딩을 기본적으로 UTF-8이라고 가정한다1.
이렇게 잘못된 인코딩을 통해 읽어온 자료를 다음과 같이 바로잡을 수 있다.
따라서 자료의 인코딩이 어떤 것으로 되어있는지를 파악하고 파일을 읽어올 때 이를 적용하여 읽어야 이러한 문제를 방지할 수 있다.
2.2 공간자료 및 공간자료의 I/O
2.2.1 공간자료의 형식 개요
GIS에서 사용하는 공간자료는 두 가지 형식으로 대별할 수 있다.
- Vector 형식(점, 선, 면 좌표 순서쌍으로 만든 그래픽)
- Esri Shapefile
- GeoJSON
- KML
- 등
- Raster 형식(격자, 이미지)
- GeoTIFF
- Erdas Imagine
- JPEG 2000
- 등
벡터 데이터는 실제 세상을 그래픽으로 재표현(graphical representation of the real world)한 것으로서, 점, 선, 다각형(points, lines, polygons) 유형의 그래픽을 이용한다. 벡터 데이터의 그래픽은 좌표의 순서쌍으로 표현할 수 있으며, 따라서 벡터 데이터는 여러 좌표의 순서쌍으로 구성된 집합이라고 말할 수 있다. 이와 더불어 각 그래픽마다 속성 정보를 가질 수 있도록 보통 데이터베이스와 연동된 경우가 대부분이다.
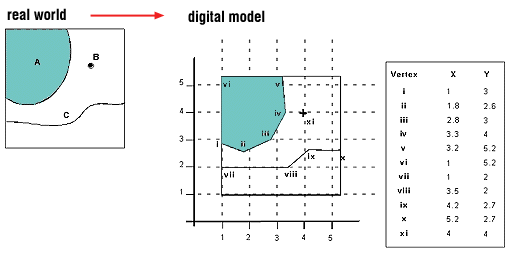
반면 레스터 데이터는 격자의 픽셀로 실제 세상을 표현한다. 다시 말하면 하나의 행렬로 지구의 표면을 표현하며, 각 원소마다 정보가 있으며, 각 원소는 지구상 어떤 지점의 좌표를 가질 수 있다. 아래 그림을 기준으로 왼쪽이 우리가 잘 아는 행렬이며, 이를 실제 좌표 공간 상에 투영한 것이 우측의 그림이다.

대표적인 공간자료 형식 중 하나인인 셰이프(.shp) 공간자료를 불러오는 법과 래스터 형식의 자료(.img)파일을 불러오는 방법을 살펴볼 것이다.
2.2.2 Vector(Polygon) 형
셰이프 파일을 불러오는 함수는 여러 개가 존재하나, 이번 실습에서는 Simple Features - sf 패키지를 사용하여 진행하고자 한다. 그리고 여러 벡터형 자료 중 Polygon으로 실습을 진행하려고 한다.
Simple Features
Overview
Simple Features 혹은 공식적으로 Simple Feature Access는 주로 2차원 지오메트리로 이루어져있는 feature2의 표준화된 스토리지 및 액세스 모델을 특정하는 표준의 집합이며 개방형 공간 정보 컨소시엄(Open Geospatial Consortium, OGC)과 국제 표준화 기구 (International Organization for Standardization, ISO)에서 공식화한 자료 형식이다. sf 패키지는 이를 R 환경에서 R 내장 자료구조(S3 classes, lists, matrix, vector)를 사용하여 네이티브 R 객체로 다룰 수 있도록 하는 패키지이다.
sf 자료형
simple features(sf)에서 속성 정보는 일반적으로 data frame 객체에 저장되며, feature의 지오메트리인 좌표의 순서쌍 또한 data frame의 한 열에 저장된다. 지오메트리는 피처의 수(레코드 수)만큼의 갯수를 가지며 이를 저장한 열을 Simple feature geometry list-column(sfc)라고 한다. 지오메트리 열의 한 레코드는 R 자료형인 list 형태로, 한 feature에 속한 단일 점 혹은 여러 꼭지점(vertex라고 함)에 해당하는 좌표를 순서쌍 형태로 저장한다. 이를 simple feature geometry(sfg)라고 한다.

위 그림에서
- 초록색으로 강조된 레코드 혹은 data frame의 한 행은 한 feature의 속성 정보와 지오메트리 정보를 가짐. 이를 Simple features(
sf)라고 함 - 파랑색으로 강조된 부분은 한 simple feature geometry(
sfg)임 -
sfg가 모여 simple feature geometry list-column(sfc)를 이룸
sf Methods
PostGIS와 유사하게 공간 데이터에서 동작하는 모든 함수와 메서드는 st_로 접두사가 붙는다. st는 spatial type를 의미하며 명렬 줄(command line)에서 자동완성 기능 사용 시 도움이 된다.
Code
?(caption)
자료 읽기
여러 공간자료 형식을 simple feature 형으로 받기 위해서는 st_read나 별칭인 read_sf를 사용하면 된다.
Simple feature collection with 250 features and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 746110.3 ymin: 1458754 xmax: 1387948 ymax: 2068444
Projected CRS: PCS_ITRF2000_TM
# A tibble: 250 × 4
SIG_CD SIG_ENG_NM SIG_KOR_NM geometry
<chr> <chr> <chr> <MULTIPOLYGON [m]>
1 11110 Jongno-gu "\xc1\xbe\xb7\xce\xb1\xb8" (((956615.5 1953567, 956…
2 11140 Jung-gu "\xc1\xdf\xb1\xb8" (((957890.4 1952617, 957…
3 11170 Yongsan-gu "\xbf\xeb\xbb\xea\xb1\xb8" (((953115.8 1950834, 953…
4 11200 Seongdong-gu "\xbc\xba\xb5\xbf\xb1\xb8" (((959681.1 1952650, 959…
5 11215 Gwangjin-gu "\xb1\xa4\xc1\xf8\xb1\xb8" (((964825.1 1952633, 964…
6 11230 Dongdaemun-gu "\xb5\xbf\xb4\xeb\xb9\xae\xb1… (((962141.9 1956519, 962…
7 11260 Jungnang-gu "\xc1\xdf\xb6\xfb\xb1\xb8" (((965698.6 1957987, 965…
8 11290 Seongbuk-gu "\xbc\xba\xba\xcf\xb1\xb8" (((956787.3 1953543, 956…
9 11305 Gangbuk-gu "\xb0\xad\xba\xcf\xb1\xb8" (((956316.8 1965175, 956…
10 11320 Dobong-gu "\xb5\xb5\xba\xc0\xb1\xb8" (((957223.8 1961200, 957…
# ℹ 240 more rows앞서서 말한 대로 인코딩이 깨져있다. 이를 바로잡으려면 다음과 같이 인코딩 옵션을 주면 된다.
Code
Simple feature collection with 250 features and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 746110.3 ymin: 1458754 xmax: 1387948 ymax: 2068444
Projected CRS: PCS_ITRF2000_TM
# A tibble: 250 × 4
SIG_CD SIG_ENG_NM SIG_KOR_NM geometry
<chr> <chr> <chr> <MULTIPOLYGON [m]>
1 11110 Jongno-gu 종로구 (((956615.5 1953567, 956621.6 1953565, 95662…
2 11140 Jung-gu 중구 (((957890.4 1952617, 957909.9 1952611, 95791…
3 11170 Yongsan-gu 용산구 (((953115.8 1950834, 953114.2 1950747, 95340…
4 11200 Seongdong-gu 성동구 (((959681.1 1952650, 959842.4 1952562, 95988…
5 11215 Gwangjin-gu 광진구 (((964825.1 1952633, 964875.6 1952606, 96490…
6 11230 Dongdaemun-gu 동대문구 (((962141.9 1956519, 962149.9 1956449, 96215…
7 11260 Jungnang-gu 중랑구 (((965698.6 1957987, 965772.3 1957944, 96584…
8 11290 Seongbuk-gu 성북구 (((956787.3 1953543, 956761.3 1953544, 95673…
9 11305 Gangbuk-gu 강북구 (((956316.8 1965175, 956401.6 1965151, 95644…
10 11320 Dobong-gu 도봉구 (((957223.8 1961200, 957195.8 1961231, 95719…
# ℹ 240 more rows인코딩 문제를 해결하고 나면, 위와 같이 정상적으로 속성 테이블을 조회할 수 있다. 이제 도시를 해보자.
tmap 패키지는 벡터, 레스터 형식의 공간자료를 레이어에 기반해서 도시할 수 있도록 하는 패키지이다. tmap의 함수 중 qtm(quick thematic map) 함수를 사용하여 도시를 하였다. 해당 패키지에 관해 더 많은 정보를 얻고 싶으면 실습지 맨 앞 링크 참고.
Warning: The shape sigungu is invalid. See sf::st_is_valid
sfc와 sfg
Simple features 자료에서 지오메트리 정보가 담긴 열인 Simple feature geometry list-column(sfc)를 다음과 같이 조회할 수 있다.
Geometry set for 250 features
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 746110.3 ymin: 1458754 xmax: 1387948 ymax: 2068444
Projected CRS: PCS_ITRF2000_TM
First 5 geometries:MULTIPOLYGON (((956615.5 1953567, 956621.6 1953...MULTIPOLYGON (((957890.4 1952617, 957909.9 1952...MULTIPOLYGON (((953115.8 1950834, 953114.2 1950...MULTIPOLYGON (((959681.1 1952650, 959842.4 1952...MULTIPOLYGON (((964825.1 1952633, 964875.6 1952...Simple feature geometry list-column(sfc)에서 한 레코드의 지오메트리 값을 저장하는 simple feature geometry(sfg)는 다음과 같이 조회가 가능하다.
아래 예시는 58번째 레코드인 인천광역시 강화군의 sfg이다.
Geometry set for 1 feature
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 863982.5 ymin: 1953854 xmax: 915596 ymax: 1981861
Projected CRS: PCS_ITRF2000_TMMULTIPOLYGON (((914233.3 1954984, 914255.6 1954...Simple feature collection with 1 feature and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 863982.5 ymin: 1953854 xmax: 915596 ymax: 1981861
Projected CRS: PCS_ITRF2000_TM
# A tibble: 1 × 4
SIG_CD SIG_ENG_NM SIG_KOR_NM geometry
<chr> <chr> <chr> <MULTIPOLYGON [m]>
1 28710 Ganghwa-gun 강화군 (((914233.3 1954984, 914255.6 1954980, 914254.4…
simple feature geometry(sfg)는 폴리곤을 구성하는 여러 vertices의 좌표 순서쌍을 R의 자료구조인 list의 형태로 담고 있다.
아래 코드를 통해 강화군을 표현하는 여러 폴리곤 중 12번째 폴리곤의 좌표 순서쌍을 확인할 수 있다.
Code
X1 X2
1 887520.8 1963684
2 887533.1 1963676
3 887548.9 1963672
4 887570.7 1963661
5 887587.7 1963657
6 887595.2 1963654위 12번째 폴리곤은 강화군 아차도리의 폴리곤으로, 다음의 코드로 도시하여 확인이 가능하다.
Code

자료 저장
간단하다. st_write 메서드를 사용하여 원하는 공간자료 형식의 확장자를 지정하여 호출하면 된다.
이렇게 출력한 파일을 다음과 같이 다른 GIS 소프트웨어에서 불러올 수 있다.

Raster 형
셰이프 파일을 불러오는 함수는 여러 개가 존재하나, 이번 실습에서는 terra 패키지를 사용하여 진행하고자 한다.
Terra
Overview
terra는 래스터와 벡터 형식의 지리적 데이터를 조작할 수 있도록 하며, 특히 래스터 데이터와 관련한 기능을 제공하며, 래스터를 만들고, 읽고, 조작하고, 쓰는 것들이 이에 속한다. 예를 들어, 파일로부터 래스터를 제작하거나 셀의 인덱스를 지리좌표로 변환하거나 역변환하는 기능이 있다. 또한 지도 대수(Map Algebra)를 포함한 래스터 데이터 조작을 위한 많은 다른 함수들을 구현한다. 네이티브 R 코드를 사용하는 raster패키지와는 다르게 terra는 C++로 빠른 행렬연산 코드를 래핑하여 제공하기 때문에 훨씬 빠른 연산을 수행할 수 있다.
이 패키지는 두 가지 주요 클래스를 가진다: SpatRaster, SpatVector. 이들 중 SpatRaster에 대해 다음 섹션에서 소개하고자 한다.
Spatraster 클래스
SpatRaster 클래스는 여러 매소드를 포함한 다양한 기능을 포함한다. 메모리(RAM)에 다 들어가지 못하는 큰 래스터 파일을 다루는 기능을 제공하며, local, focal, zonal, global 및 지도 대수(map algebra) 같은 여러 래스터 연산기능과 백터형 자료와 래스터형 간 변환이 가능하다. 또한, 공간적 예측(spatial prediction)을 하기 위한 여러 모형과의 통합을 제공한다.
SpatRaster를 포함한 여러 terra 패키지의 클래스가 할당한 R 변수에는 C++ 포인터(C++의 변수로 저장된 Rcpp_SpatRaster class의 주소값)로 저장되기 때문에 R 세션이 달라지거나(i.e. R을 재시작 하였거나) 병렬 연산을 위해 직접 컴퓨터 클러스터의 노드에 전달되어서는 않 된다. 따라서 RData 형식으로 저장하고 불러올 시 오류가 발생하기 때문에 WriteRaster() 메서드를 사용하여 저장 후 사용하여야 한다.
자료 읽기
래스터 자료를 rast()를 사용하여 SpatRaster 형식으로 불러올 수 있다.
아래 코드는 Erdas Imagine(.img) 형식의 래스터 파일을 SpatRaster로 불러온 뒤 간단한 도시를 하는 코드이다.
Code

SpatRaster를 지정한 변수를 출력하여 불러온 DEM 래스터의 속성정보를 확인할 수 있다.
class : SpatRaster
dimensions : 1037, 1256, 1 (nrow, ncol, nlyr)
resolution : 30, 30 (x, y)
extent : 302232.6, 339912.6, 4143913, 4175023 (xmin, xmax, ymin, ymax)
coord. ref. : WGS_1984_UTM_Zone_52N (EPSG:32652)
source : seoul_dem.img
name : Layer_1
min value : 1.039576
max value : 737.355835 앞서 설명하였듯이 DEM을 저장한 R 변수에는 C++ 포인터가 적재되어 있다.
자료 저장
simple feature와 유사하게 다음과 같이 여러 래스터 자료형으로 저장할 수 있으며, 다른 GIS 소프트웨어에서도 사용이 가능하다.
아래와 같이 ArcMap 10.8에서 정상적으로 불러오는 것이 가능하다.

과연 Raster는 행렬일까?

위에서 설명한 이론 자료를 직접 확인하는 섹션을 만들어보았다. 기존 R의 행렬과 관련된 작업이 느려, 먼저 불러온 DEM SpatRaster의 해상도를 30M \(\times\) 30M(1037,1256)에서 120M \(\times\) 120M(260,314)로 줄였다. 즉 래스터의 픽셀 혹은 행렬 원소의 수가 1,302,472개에서 81,640개(기존 대비 6%)로 줄어 연산을 수행하는 양을 줄였다.
class : SpatRaster
dimensions : 260, 314, 1 (nrow, ncol, nlyr)
resolution : 120, 120 (x, y)
extent : 302232.6, 339912.6, 4143823, 4175023 (xmin, xmax, ymin, ymax)
coord. ref. : WGS_1984_UTM_Zone_52N (EPSG:32652)
source(s) : memory
name : Layer_1
min value : 3.864079
max value : 695.421326 Code

2차원 평면인 래스터에서 각 픽셀의 값을 추출하려면 내포 혹은 이중 반복문(nested for loop)을 사용하여야 하지만 매우 느린 작업이므로 벡터화 연산을 사용하여 래스터 셀의 값을 1차원 벡터로 추출하였다.
Code
[1] 3.864079 695.421326벡터 형식으로 추출한 래스터의 값을 재배열하여 2차원 배열로 바꾸었으며, 래스터와 동일한 차원과 행, 열의 수를 갖도록 하였다.
행 우선(row-major) 배열을 사용하는 C++ 특성상 terra의 C++ 클래스로부터 래스터의 값을 추출할 시 2차원 배열에서 행(가로)방향으로 먼저 값이 추출되었다. 반면, R은 열 우선(column-major) 배열을 사용하기 때문에 byrow = TRUE 옵션을 지정하였다.
아래 코드를 사용하여 행렬로 변환한 래스터를 도시할 수 있다.
Code
Warning: package 'plot.matrix' was built under R version 4.2.3
지리좌표 공간(coordinate space)이 아닌 점을 제외하면 래스터와 동일함을 볼 수 있다. 이러한 특성을 활용하여 뒤에서 다룰 위성영상 자료(래스터 형식)를 배열(행렬)로 변환 후 여러 예측 모형에서 사용할 수 있다. 개념을 알아두면 좋을 것 같아 실습 자료에 포함하였다.
좌표체계(Coordinate System)
읽으면 도움 많이 됨!
좌표체계를 설명하자면 한도 끝도 없으나, 지도학 강좌를 수강하였다는 가정 하에 TA의 경험 상 많이 사용하고, 햇갈리는 개념을 위주로 준비해봤다.
지리좌표계인 WGS 1984는 위,경도로 위치를 표현하고, 투영좌표계인 UTM이나 소위 말하는 중부원점은 왜 meter 단위로 좌표를 표현하는 것을 본 적이 있으며, 이에 궁금한 적이 있는가? 이 섹션은 이에 대한 답을 줄 수도 있다.
지구상의 위치를 나타내는 좌표계는 지리좌표계(GCS)와 투영좌표계(PCS)로 크게 구분할 수 있다.
먼저 지리좌표계(Geographical Coordinate System, GCS)는 지구를 어떤 회전 타원체(지구 타원체)로 정의하고 그 타원체의 표면 위치를 구면좌표계(spherical coordinate system)로 나타내는 것을 의미한다.
구면좌표계는 3가지 변수\((r,\theta,\phi)\)를 통해 3차원 구 표면의 좌표를 나타낼 수 있다. 우측 그림을 기준으로 좌표계로 나타내고자 하는 지점을 P라고 할 때
-
\(r\): 원점으로부터 P까지의 거리
- 범위: \(r\ge 0\)
-
\(\theta\): z축의 양의 방향으로부터 원점과 P가 이루는 직선까지의 각
- 범위: \(0\le \theta \le \pi\), 단위는 라디안.

-
\(\phi\): x축의 양의 방향으로부터 원점과 P가 이루는 직선을 xy평면에 투영시킨 직선까지의 각.
- 범위: \(0\le \phi \lt 2\pi\), 단위는 라디안.
눈치 챘을 수도 있지만, 여기서 \(\theta\)와 \(\phi\), 위도와 경도와 개념이 유사하지 않은가?
실제로 x축의 양의 방향이 구 표면에 닿는 위치를 본초 자오선(prime meridian)이라고 두면, \(\pi-\phi\)는 경도, \(\frac{\pi}{2}-\theta\)는 위도라고 볼 수 있으며 남은 \(r\)은 지구 타원체3의 반경이라고 볼 수 있다.

따라서 GCS는 3차원 구면좌표계라고 볼 수 있으며, 좌표의 단위는 각도의 단위인 도(°, \(\deg\))로 나타내는 것이다. 아래 sf 형식의 공간자료에서 좌표계 조회를 할 수 있는 st_crs 메소드의 결과에서도 확인할 수 있다.
Coordinate Reference System:
User input: EPSG:4326
wkt:
GEOGCRS["WGS 84",
ENSEMBLE["World Geodetic System 1984 ensemble",
MEMBER["World Geodetic System 1984 (Transit)"],
MEMBER["World Geodetic System 1984 (G730)"],
MEMBER["World Geodetic System 1984 (G873)"],
MEMBER["World Geodetic System 1984 (G1150)"],
MEMBER["World Geodetic System 1984 (G1674)"],
MEMBER["World Geodetic System 1984 (G1762)"],
MEMBER["World Geodetic System 1984 (G2139)"],
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]],
ENSEMBLEACCURACY[2.0]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
CS[ellipsoidal,2],
AXIS["geodetic latitude (Lat)",north,
ORDER[1],
ANGLEUNIT["degree",0.0174532925199433]],
AXIS["geodetic longitude (Lon)",east,
ORDER[2],
ANGLEUNIT["degree",0.0174532925199433]],
USAGE[
SCOPE["Horizontal component of 3D system."],
AREA["World."],
BBOX[-90,-180,90,180]],
ID["EPSG",4326]]GIS 툴로 feature 간 거리계산을 할 때는 공간자료의 좌표계가 GCS가 아닌 PCS로 계산하도록 하자. GCS로 계산하면 상기의 이유로 보통 도(\(\deg\)) 단위의 거리가 산출된다.
그런데 보통 우리는 meter 단위의 거리를 원하지 않는가?
다음은 투영좌표계(Projected Coordinate System)이며, 우리나라에서 자주 쓰이는 투영 좌표계는 전지구 좌표계로는 UTM zone 52N(EPSG:32652)가 있으며, 우리나라 좌표계로는 대표적으로 국토지리정보원 표준인 서부원점(EPSG:5185), 중부원점(EPSG:5186), 동부원점(EPSG:5187), 동해원점(EPSG:5188)이 있다.
PCS는 앞서 설명한 GCS를 평면상에 투영함으로써 3차원의 지구를 2차원의 평면으로 옮긴 좌표계를 의미한다. 투영법은 아주 다양하나 여기에서는 다루지 않겠다. 다른 강좌의 강의자료나 교과서를 참고하기를 바란다.
보통 공간자료의 제작은 과거에는 도화기, 현재는 컴퓨터 화면과 같은 평면에서 이루어진다. 평면은 데카르트 혹은 직각좌표계로 그 위치를 표현할 수 있다. 공간자료를 제작할 때 이루어진 측량은 보통 길이 단위인 미터(meter) 혹은 피트(feet) 단위로 이루어지기 때문에, 해당 평면에 대응하는 좌표계의 단위는 이러한 길이 단위로 이루어져 있다.

지리좌표계가 구면좌표계에 대응하듯, 투영좌표계는 직각좌표계에 대응하며, 변수는 \((x,y)\) 두 변수로 이루어져있다. 단위는 보통 미터(meter)를 사용한다.
Code
Coordinate Reference System:
User input: EPSG:5186
wkt:
PROJCRS["Korea 2000 / Central Belt 2010",
BASEGEOGCRS["Korea 2000",
DATUM["Geocentric datum of Korea",
ELLIPSOID["GRS 1980",6378137,298.257222101,
LENGTHUNIT["metre",1]]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4737]],
CONVERSION["Korea Central Belt 2010",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",38,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",127,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",1,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",200000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",600000,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["northing (X)",north,
ORDER[1],
LENGTHUNIT["metre",1]],
AXIS["easting (Y)",east,
ORDER[2],
LENGTHUNIT["metre",1]],
USAGE[
SCOPE["Cadastre, topographic mapping."],
AREA["Republic of Korea (South Korea) - onshore between 126°E and 128°E."],
BBOX[33.14,126,38.33,128]],
ID["EPSG",5186]]투영좌표계의 투영법과 매개 변수(투영 원점, false northing, false easting)에 따라서 x축과 y축의 값이 천차만별이다. 따라서 공간자료가 투영자료라면 제작자가 어느 투영법을 사용하여 자료를 제작하였는지 확인하는 것이 매우 중요하다.
예를 들어 다음과 같은 경우가 있을 수 있다. 어느 정부기관에서 구득한 자료가 가짜 편북 값(false northing)이 600,000m인 Korea 2000 / Central Belt 2010를 가지고 제작하였으나, 연구자가 임의로 가북이 500,000m인 Korea 2000 / Central Belt로 좌표를 정의하였을 때 일어날 수 있는 일이다.
Code
# 원래 자료 좌표계: 제주도 포함 중부원점(Korea 2000 / Central Belt 2010)
# false-northing 600,000m
right_pcs <- read_sf("./data/shp/구/kr_si_gun-gu.shp",
options = "ENCODING=cp949")[1:25,] %>%
st_make_valid() %>%
st_transform(5186)
# 좌표계 강제 부여한 실험 데이터
# 제주도 미포함 중부원점(Korea 2000 / Central Belt)
# false-northing 500,000m
wrong_pcs <- right_pcs
st_crs(wrong_pcs) <- st_crs(5181)Warning: st_crs<- : replacing crs does not reproject data; use st_transform for
thatCode
# OSM을 위한 범위
bndbox <- st_bbox(right_pcs)
bndbox[[4]] <- bndbox[[4]]+100000
# 도시
# 빨강-잘못된 좌표계 정의
# 파랑-올바른 좌표계 정의
read_osm(bndbox) %>%
st_transform(5186) %>%
tm_shape() + tm_rgb() +
tm_shape(wrong_pcs) +
tm_polygons(border.col="red", alpha = 0)+
tm_shape(right_pcs) +
tm_polygons(border.col="blue", alpha = 0)+
tm_grid(alpha =1,
ticks = T,
lines = F)
위와 같이 지도가 가짜 편북 값(100,000m)의 차만큼 평행이동한 것을 볼 수 있다.
2.2.3 좌표계 정의
ArcGIS의 Define Projection과 같은 내용이다.
우리나라 데이터 센터에서 제공하는 일부 셰이프 파일은 좌표 메타데이터 파일인 파일명.prj 파일이 없는 경우도 있다.
아래와 같이 좌표투영이 되어있지 않은 파일은 GIS 프로그램 상에 올릴 시 다음과 같이 올바르게 도시되지 않는다.
Code
Warning: Current projection of shape seoulemd unknown and cannot be determined.
따라서 해당 자료 제작 시 어떠한 좌표 체계를 사용하였는지 파악하는게 중요하다.
아래의 예시는 구득 웹 사이트(국가공간정보포털 오픈마켓) 상에서 메타데이터를 확인하고, 지리원 표준 좌표계 중 하나인 ‘EPSG:5181’(중부원점, GRS80)로 좌표계를 다음과 같이 정의하였다.
Code

2.2.4 좌표계 변경
ArcGIS의 Project 툴과 비슷한 기능이다. 타원체와 투영법이 다른 두 가지의 공간자료를 가지고 작업을 할 때 필수적으로 해야하는 작업이다.
가령, 아래와 같이 범위가 큰 래스터 자료를 사례지역으로 잘라내고 싶을 때 해당 래스터와 범위 자료가 서로 좌표체계가 다를 경우, 공간 연산이 불가능하다.
Code
seoulgwanak <- subset(right_pcs, SIG_KOR_NM == "관악구") # 관악구 경계만 추출
# Extract by mask(벡터 파일의 clip연산과 유사)
# 관악구 경계를 가지고 서울시 DEM을 관악구만 추출
# 작업이 행해지는 객체(Object) 대신
# 작업의 흐름을 강조하기 위해 '%>%'를 사용함
# '%>%'는 '파이프' 연산자라고 칭하고 'tidyverse' 패키지에 포함
# https://style.tidyverse.org/pipes.html <- 참고
DEMgwanak <- terra::crop(seoulDEM30, extent(seoulgwanak), snap="out") %>%
terra::mask(mask = seoulgwanak)Error in h(simpleError(msg, call)): error in evaluating the argument 'x' in selecting a method for function 'mask': [crop] extents do not overlap에러 메시지 상으로도 두 공간자료가 중첩되지 않는다고 나타난다.
따라서 이런 경우에는 좌표체계를 동일한 좌표체계를 사용하게끔 변환해줘야한다.
위에서 사용한 두 공간자료의 좌표체계는 다음과 같다.
Coordinate Reference System:
User input: EPSG:5186
wkt:
PROJCRS["Korea 2000 / Central Belt 2010",
BASEGEOGCRS["Korea 2000",
DATUM["Geocentric datum of Korea",
ELLIPSOID["GRS 1980",6378137,298.257222101,
LENGTHUNIT["metre",1]]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4737]],
CONVERSION["Korea Central Belt 2010",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",38,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",127,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",1,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",200000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",600000,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["northing (X)",north,
ORDER[1],
LENGTHUNIT["metre",1]],
AXIS["easting (Y)",east,
ORDER[2],
LENGTHUNIT["metre",1]],
USAGE[
SCOPE["Cadastre, topographic mapping."],
AREA["Republic of Korea (South Korea) - onshore between 126°E and 128°E."],
BBOX[33.14,126,38.33,128]],
ID["EPSG",5186]]Coordinate Reference System:
User input: WGS_1984_UTM_Zone_52N
wkt:
PROJCRS["WGS_1984_UTM_Zone_52N",
BASEGEOGCRS["WGS 84",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4326]],
CONVERSION["UTM zone 52N",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",0,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",129,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",0.9996,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",500000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",0,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["(E)",east,
ORDER[1],
LENGTHUNIT["meters",1]],
AXIS["(N)",north,
ORDER[2],
LENGTHUNIT["meters",1]],
ID["EPSG",32652]]관악구 경계는 GRS80 타원체의 UTM-K 좌표계를 가지고 있는데 반해 서울시 DEM은 WGS84 타원체의 UTM zone 52N 좌표계를 지니고 있다.
따라서 둘 중 하나의 좌표계를 다른 것과 동일하게 맞춰야 하는데, 관악구 경계를 DEM의 좌표계와 동일하게 변경하면 된다. 방법은 벡터 데이터를 변환하거나, 아니면 래스터 데이터를 변환하는 것 두 가지가 존재한다.
벡터 자료 좌표계 변환(sf::st_transform)
Code
Coordinate Reference System:
User input: EPSG:32652
wkt:
PROJCRS["WGS 84 / UTM zone 52N",
BASEGEOGCRS["WGS 84",
ENSEMBLE["World Geodetic System 1984 ensemble",
MEMBER["World Geodetic System 1984 (Transit)"],
MEMBER["World Geodetic System 1984 (G730)"],
MEMBER["World Geodetic System 1984 (G873)"],
MEMBER["World Geodetic System 1984 (G1150)"],
MEMBER["World Geodetic System 1984 (G1674)"],
MEMBER["World Geodetic System 1984 (G1762)"],
MEMBER["World Geodetic System 1984 (G2139)"],
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]],
ENSEMBLEACCURACY[2.0]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4326]],
CONVERSION["UTM zone 52N",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",0,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",129,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",0.9996,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",500000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",0,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["(E)",east,
ORDER[1],
LENGTHUNIT["metre",1]],
AXIS["(N)",north,
ORDER[2],
LENGTHUNIT["metre",1]],
USAGE[
SCOPE["Engineering survey, topographic mapping."],
AREA["Between 126°E and 132°E, northern hemisphere between equator and 84°N, onshore and offshore. China. Indonesia. Japan. North Korea. Russian Federation. South Korea."],
BBOX[0,126,84,132]],
ID["EPSG",32652]]Code
tmap mode set to interactive viewingCode
래스터 자료 좌표계 변환(terra::project)
terra의 project() 함수는 SpatRast 공간자료의 좌표재투영을 할 수 있도록 하며, 다중스레드 작업을 지원하여 raster보다 빠른 작업 속도를 낼 수 있도록 한다.
Code
Coordinate Reference System:
User input: Korea 2000 / Central Belt 2010
wkt:
PROJCRS["Korea 2000 / Central Belt 2010",
BASEGEOGCRS["Korea 2000",
DATUM["Geocentric datum of Korea",
ELLIPSOID["GRS 1980",6378137,298.257222101,
LENGTHUNIT["metre",1]]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4737]],
CONVERSION["Korea Central Belt 2010",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",38,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",127,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",1,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",200000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",600000,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["northing (X)",north,
ORDER[1],
LENGTHUNIT["metre",1]],
AXIS["easting (Y)",east,
ORDER[2],
LENGTHUNIT["metre",1]],
USAGE[
SCOPE["Cadastre, topographic mapping."],
AREA["Republic of Korea (South Korea) - onshore between 126°E and 128°E."],
BBOX[33.14,126,38.33,128]],
ID["EPSG",5186]]Code
tmap mode set to interactive viewingCode
3 API를 사용한 Geocoding
3.1 이론
3.1.1 Geocoding이란?
일반적으로 지오코딩(geocoding)이라는 용어는 사람이 읽을 수 있는 주소를 지도상의 위치인 좌표로 변환하는 과정을 가리킨다. 반대로 지도상의 좌표를 사람이 읽을 수 있는 주소로 변환하는 과정은 역 지오코딩(reverse geocoding)이라고 한다. ArcGIS 등 여러 상용 소프트웨어 및 지도 서비스에서 해당 서비스를 제공한다.

본 실습은 올리브영 매장안내 웹페이지의 정보를 크롤링한 자료를 가지고 NAVER API를 사용하여 지오코딩을 수행한 과정을 담았다.
추가적으로 점 패턴 분석을 위해 공간 조인(spatial join) 과정도 포함하였다.
3.1.2 API란?
API는 Application Programming Interface의 줄임말이다. 여기서 ‘Application’이라는 단어는 고유한 기능을 가진 모든 소프트웨어를 의미한다. ‘Interface’는 두 ‘Application’ 사이의 서비스 계약이라고 할 수 있다. 이 계약은 요청과 응답을 사용하여 두 ‘Application’이 서로 통신하는 방법을 정의한다.
정리하자면, API는 정의 및 프로토콜 집합을 사용하여 두 소프트웨어 구성 요소가 서로 통신할 수 있게 하는 메커니즘이다. 예를 들어, 기상청의 소프트웨어(‘Application’) 시스템에는 일일 기상 데이터가 들어 있다. 휴대폰의 날씨 ‘Application’은 API를 통해 이 시스템과 ’대화’하여 휴대폰에 매일 최신 날씨 정보를 표시한다.
3.2 코드
3.2.1 웹 크롤링
RSelenium은 다음의 설정을 요구한다.
사용한 웹 크롤러는 R 패키지인 RSelenium을 사용하여 진행하였다. 환경 설정 관련한 자세한 설명은 위 청크에 있는 웹 페이지를 참고 바란다.
모든 크롤링 및 스크래핑은 완전 자동화를 지향하여 코딩하였다.
Code
#install.packages("RSelenium")
library(RSelenium)
#Start the web driver
driver <- rsDriver(browser = "chrome", port = 4445L)
#Say 'I'm a client'
remote_driver <- driver[["client"]]
#Send to browser the web site address
remote_driver$navigate("https://www.oliveyoung.co.kr/store/store/getStoreMain.do?trackingCd=Store_Recommend_Best")
#지역검색으로 넘어가기
remote_driver$findElement(using = "id",value = "searchAreaTab")$clickElement()
# 드롭다운 메뉴에서 서울시 선택
#remote_driver$findElement(using = 'xpath', "//*/option[@value = '서울특별시']")$clickElement()
# iframe? 내부 스크롤 박스 선택
scroll_d <- remote_driver$findElement(using = "xpath", value = '//*[@id="mCSB_3"]')
# 자동스크롤
oldhgt <- scroll_d$executeScript("return document.getElementById('mCSB_3').scrollHeight") %>%
unlist()
scroll_d$sendKeysToElement(list(key = "end"))
newhgt <- scroll_d$executeScript("return document.getElementById('mCSB_3').scrollHeight") %>%
unlist()
while (oldhgt!=newhgt) {
oldhgt <- newhgt
scroll_d$sendKeysToElement(list(key = "end"))
Sys.sleep(1)
newhgt <- scroll_d$executeScript("return document.getElementById('mCSB_3').scrollHeight") %>%
unlist()
}
library(rvest)
library(xml2)
html.olive <- read_html(scroll_d$getElementAttribute("outerHTML")[[1]],
encoding = "UTF-8")
driver$server$stop()
name <- html_nodes(html.olive, css="a") %>%
as.character() %>%
str_remove('<a href="javascript:;">') %>%
str_remove('</a>')
addr <- html_nodes(html.olive, css=".addr") %>%
as.character() %>%
str_remove('<p class="addr">') %>%
str_remove('</p>')
ph.numb <- html_nodes(html.olive, css=".call") %>%
as.character() %>%
str_remove('<div class="call">') %>%
str_remove('</div>')
noi <- html_nodes(html.olive, css=".fv_reShop_in") %>%
html_nodes("span") %>%
as_list() %>%
unlist(use.names=FALSE) %>%
str_remove(',')
olive <- cbind(name,addr,ph.numb,noi) %>%
as.data.frame(stringsAsFactors=FALSE)
olive$noi <- as.integer(olive$noi)수집한 자료는 불완전할 수 있다. 예시의 자료만 하더라도 오류가 있어 다음과 같이 바로잡아주었다.
Code
{
olive$addr[olive$name=="사당역지하상가점"] <- "서울 동작구 동작대로 3"
olive$addr[olive$name=="강남엔터식스점"] <- "서울 서초구 신반포로 188"
olive$addr[olive$name=="광명철산점"] <- "경기 광명시 철산로 24"
olive$addr[olive$name=="안양일번가지하상가점"] <- "경기 안양시 만안구 만안로 231"
olive$addr[olive$name=="국회의사당역점"] <- "서울 영등포구 국회대로 758"
olive$addr[olive$name=="양재역점"] <- "서울특별시 서초구 양재동 19-14"
olive$addr[olive$name=="신논현역점"] <- "서울 강남구 봉은사로 102"
olive$addr[olive$name=="염창역9호선점"] <- "서울 강서구 공항대로 631"
olive$addr[olive$name=="디지털미디어시티역점"] <- "서울 마포구 성암로 197"
olive$addr[olive$name=="천호엔터식스점"] <- "서울 강동구 천호대로 997"
olive$addr[olive$name=="수원금곡점"] <- "경기 수원시 권선구 금곡로 213"
olive$addr[olive$name=="광주오포점"] <- "경기 광주시 신현로 113"
olive$addr[olive$name=="인천터미널역점"] <- "인천 미추홀구 예술로 85"
olive$addr[olive$name=="AK기흥점"] <- "경기도 용인시 기흥구 구갈동 660"
olive$addr[olive$name=="블로썸캠퍼스진천점"] <- "충청북도 진천군 진천읍 송두리 833"
olive$addr[olive$name=="제천점"] <- "충청북도 제천시 풍양로13길 6"
olive$addr[olive$name=="대전중앙지하상가점"] <- "대전광역시 중구 선화동 383"
olive$addr[olive$name=="대구반월당점"] <- "대구 중구 달구벌대로 2100"
olive$addr[olive$name=="동대구지하철역점"] <- "대구 동구 동대구로 530"
olive$addr[olive$name=="서면역사점"] <- "부산 부산진구 중앙대로 730"
olive$addr[olive$name=="제주중앙지하상가점"] <- "제주특별자치도 제주시 일도일동 1426-5"
}
head(olive)# A tibble: 6 × 4
name addr ph.numb noi
<chr> <chr> <chr> <dbl>
1 녹두거리점 서울특별시 관악구 신림로 127 1층 02-885-… 2526
2 낙성대점 서울특별시 관악구 남부순환로 1908 대원빌딩 … 02-879-… 2495
3 서울대입구역점 서울특별시 관악구 남부순환로 1840 02-884-… 4840
4 올리브영 관악 타운 서울특별시 관악구 관악로 171 02-883-… 6767
5 낙성대인헌점 서울특별시 관악구 남부순환로248길 3 1층 02-875-… 1498
6 봉천역점 서울특별시 관악구 남부순환로 1735 02-876-… 17413.2.3 Spatial join
앞선 실습에서 다루었던 전국 시군구 자료(변수명: sigungu)를 가지고 공간 조인을 수행하였다. 추후 포인트 패턴 분석에서 사용될 수 있으므로 참고.
sf 패키지를 사용한 공간 조인을 수행하였다. sf 패키지와 dplyr 패키지를 같이 사용하면 ArcGIS 부럽지 않은 공간 조인을 수행할 수 있다.
공간 조인을 위해서는 두 자료의 좌표계가 일치하여야 한다.
3.2.3.1 큰 스케일 공간자료 속성정보 -> 작은 스케일 공간자료
큰 스케일 공간자료인 시군구 sf의 속성정보를 점 단위의 작은 스케일인 올리브영 자료에 조인하였다.
보통, 조인이라고 하면 key를 사용하여 두 테이블의 자료를 합치는데, 공간 조인은 두 공간자료의 공간연산을 통해 위상을 파악 후 이를 key로 사용한다.
가령 아래의 예시의 경우 공간연산(intersect)를 통해 시군구 sf의 각 feature(전국 250개 시군구)안에 위치하는 올리브영 매장을 파악한 뒤, 이 정보를 key로 삼아 각 올리브영 매장의 속성정보에 집어넣는다.
Code
joined <- st_join(sf_olive,sigungu, join = st_intersects)
{# 지도 한방에 그리기
tm_basemap(c("OpenStreetMap.HOT",
"https://mt1.google.com/vt/lyrs=y&hl=en&z={z}&x={x}&y={y}",
"https://mt1.google.com/vt/lyrs=s&hl=en&z={z}&x={x}&y={y}"),
group = c("OpenStreetMap.HOT",
"Google Satellite Imagery w/ label",
"Google Satellite Imagery wo/ label")) +
tm_shape(joined) +
tm_dots(size=.1,
col = "red",
border.col="white",
border.lwd=3,
id="name") -> themap
tmap_leaflet(themap)|>
addMouseCoordinates()
}Warning in is.na(group) && !is.null(names(server)): 'length(x) = 3 > 1' in
coercion to 'logical(1)'Code
Joining with `by = join_by(SIG_CD)`
3.2.3.2 작은 스케일 공간자료 속성정보 -> 큰 스케일 자료
이번에는 반대로 작은 스케일 point 자료의 속성정보인 관심고객 수(noi)를 큰 스케일의 공간자료인 시군구 자료에 넣어보았다.
하지만 이전과는 다르게 공간 조인을 수행하면 하나의 시 혹은 군, 구에 여러 올리브영 매장의 속성이 있을 수 있다. 따라서 dplyr 패키지의 강력한 기능 중 하나인 group_by() %>% summarise()를 통해 한 피처 안에 위치한 여러 매장의 noi 값을 합산하여, 하나의 sigungu feature 당 하나의 noi 속성 값을 가지도록 하였다.
Code
Joining with `by = join_by(SIG_CD)`Code
Joining with `by = join_by(SIG_CD)`

4 Remote Sensing in R
본 섹션에서는 terra 패키지와 rgee 패키지를 사용하여 원격탐사 데이터를 다뤄보고자 한다.
크게 로컬 환경과 클라우드 환경에서 분석을 수행할 예정인데, 클라우드 환경은 Google Earth Engine을, 로컬 환경은 terra 패키지를 주로 활용하였다.
4.1 RS using Terra
ArcGIS의 Raster calculator 인 지도 대수(Map Algebra)를 사용하여 정규 식생지수(NDVI)를 구하는 과정이다.
R의 raster 패키지를 사용하면 위성영상의 활용도 충분히 수행할 수 있다.
다음의 예제는 Landsat 8 OLI 영상을 사용한다. 대기보정(Surface Reflectance, Collection 1)한 세종시 영상을 가지고 NDVI를 구하였다.
참고: Operational Land Imager (OLI)
- Nine spectral bands, including a pan band:
- Band 1 Coastal Aerosol (0.43 - 0.45 µm) 30 m
- Band 2 Blue (0.450 - 0.51 µm) 30 m
- Band 3 Green (0.53 - 0.59 µm) 30 m
- Band 4 Red (0.64 - 0.67 µm) 30 m
- Band 5 Near-Infrared (0.85 - 0.88 µm) 30 m
- Band 6 SWIR 1(1.57 - 1.65 µm) 30 m
- Band 7 SWIR 2 (2.11 - 2.29 µm) 30 m
- Band 8 Panchromatic (PAN) (0.50 - 0.68 µm) 15 m
- Band 9 Cirrus (1.36 - 1.38 µm) 30 m
- radiometric resolution: over a 12-bit dynamic range(4096 potential grey levels)
먼저 밴드의 수를 확인한다. Stackted raster의 경우 nlyr() 함수를 사용하여 적층된 래스터 레이어의 수를 확인할 수 있다.
앞서 설명한 대로 rast() 함수를 사용하여 불러왔다.
class : SpatRaster
dimensions : 1215, 831, 9 (nrow, ncol, nlyr)
resolution : 30, 30 (x, y)
extent : 332745, 357675, 4030485, 4066935 (xmin, xmax, ymin, ymax)
coord. ref. : WGS 84 / UTM zone 52N (EPSG:32652)
source : LC08_116035_20210330_clip.tif
names : Layer_1, Layer_2, Layer_3, Layer_4, Layer_5, Layer_6, ...
min values : NA, NA, NA, NA, 0, 0, ...
max values : 6490, 6048, 5382, 5886, 6800, 15357, ... NDVI는 다음과 같은 식으로 구할 수 있으므로…
\[ \text{NDVI} = \frac{\text{NIR}-\text{RED}}{\text{NIR}+\text{RED}} \]
위의 식을 R 코드로 작성하면 다음과 같다. spatrast 클래스에서 원하는 레이어를 추출하는 방법은 spatrast객체명[[레이어번호]] 로 가능하다.
tmap mode set to interactive viewingCode
stars object downsampled to 827 by 1209 cells. See tm_shape manual (argument raster.downsample)
4.2 R Google Earth Engine(rgee)
4.2.1 초기 설정
4.2.1.1 회원가입
Google Earth Engine을 사용하려면 다음의 웹 페이지에서 회원가입을 요한다. https://earthengine.google.com/signup/
4.2.1.2 Google Cloud Platform
rgee를 사용하기 위해서는 Google Cloud Platform(gcloud)을 터미널에서 설치를 필요로 한다.
다음 코드를 터미널에 입력한다.
(New-Object Net.WebClient).DownloadFile("https://dl.google.com/dl/cloudsdk/channels/rapid/GoogleCloudSDKInstaller.exe", "$env:Temp\GoogleCloudSDKInstaller.exe")
& $env:Temp\GoogleCloudSDKInstaller.exe4.2.1.3 환경 설정
rgee는 Google Earth Engine 파이썬 API를 사용하기 때문에, 다음과 같은 코드로 Python Miniconda 환경과 연동하여야 작동한다.
모두 설치가 되었으면 ee_check()로 GEE가 작동하는데 필요한 파이썬 요소를 확인하여야 한다.
Code
◉ Python version
✔ [Ok] C:/Users/dydgn/AppData/Local/r-miniconda/envs/rgee/python.exe v3.8
◉ Python packages:
✔ [Ok] numpy
✔ [Ok] earthengine-api모두 정상이라면 ee_Initialize()를 통해 사용자 인증 및 API 초기화를 시켜준다. 과정 중에 인터넷 창이 뜨면서 앞서 회원가입한 구글계정에 대하여 정보를 요구할 수도 있다.
── rgee 1.1.5 ─────────────────────────────────────── earthengine-api 0.1.323 ──
✔ user: not_defined
✔ Google Drive credentials:Auto-refreshing stale OAuth token.
✔ Google Drive credentials: FOUND
✔ Initializing Google Earth Engine:
✔ Initializing Google Earth Engine: DONE!
✔ Earth Engine account: users/dydgn
──────────────────────────────────────────────────────────────────────────────── 4.2.2 Landsat 5 NDVI
4.2.2.1 관심지역 공간자료
세종시를 사례로 분석을 진행하기 위하여 세종시 셰이프 파일을 sf 형식으로 불러왔다.
대기보정이 완료된 SR(Surface Reflectance) 자료를 사용하여 NDVI를 구하는 코드이다.
Registered S3 method overwritten by 'geojsonsf':
method from
print.geojson geojsonCode
──────────────────────────────────────────────── Earth Engine ImageCollection ──
ImageCollection Metadata:
- Class : ee$ImageCollection
- Number of Images : 1
- Number of Properties : 34
- Number of Pixels* : 382967585
- Approximate size* : 2.45 GB
Image Metadata (img_index = 0):
- ID : LANDSAT/LT05/C01/T1_SR/LT05_115035_20040409
- system:time_start : 2004-04-09 01:44:46
- Number of Bands : 7
- Bands names : B1 B2 B3 B4 B5 B6 B7
- Number of Properties : 22
- Number of Pixels* : 382967585
- Approximate size* : 2.45 GB
Band Metadata (img_band = 'B1'):
- EPSG (SRID) : WGS 84 / UTM zone 52N (EPSG:32652)
- proj4string : +proj=utm +zone=52 +datum=WGS84 +units=m +no_defs
- Geotransform : 30 0 272985 0 -30 4096515
- Nominal scale (meters) : 30
- Dimensions : 7735 7073
- Number of Pixels : 54709655
- Data type : INT
- Approximate size : 358.62 MB
────────────────────────────────────────────────────────────────────────────────
NOTE: (*) Properties calculated considering a constant geotransform and data type.────────────────────────────────────────────────────────── Earth Engine Image ──
Image Metadata:
- Class : ee$Image
- ID : LANDSAT/LT05/C01/T1_SR/LT05_115035_20040409
- system:time_start : 2004-04-09 01:44:46
- Number of Bands : 7
- Bands names : B1 B2 B3 B4 B5 B6 B7
- Number of Properties : 22
- Number of Pixels* : 382967585
- Approximate size* : 2.45 GB
Band Metadata (img_band = B1):
- EPSG (SRID) : WGS 84 / UTM zone 52N (EPSG:32652)
- proj4string : +proj=utm +zone=52 +datum=WGS84 +units=m +no_defs
- Geotransform : 30 0 272985 0 -30 4096515
- Nominal scale (meters) : 30
- Dimensions : 7735 7073
- Number of Pixels : 54709655
- Data type : INT
- Approximate size : 358.62 MB
────────────────────────────────────────────────────────────────────────────────
NOTE: (*) Properties calculated considering a constant geotransform and data type.NOTE: Center obtained from the first element.Code
ee_as_raster()로 클라우드 환경의 데이터를 로컬로 가져올 수 있다.
Code
ee_as_raster(
aoi,
region = geometry$geometry()$bounds(),
#dsn = NULL,
via = "drive", # via 사용자 구글 드라이브
#container = "rgee_backup",
scale = 30, # Scale은 공간해상도 - 30m
#maxPixels = 1e+09,
#lazy = FALSE,
#public = TRUE,
#add_metadata = TRUE,
#timePrefix = TRUE,
#quiet = FALSE,
#...
) %>% rast() -> outras - region parameters
sfg : POLYGON ((127.1277 36.40676 .... 6.73382, 127.1277 36.40676))
CRS : GEOGCRS["WGS 84",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563, .....
geodesic : FALSE
evenOdd : TRUE
- download parameters (Google Drive)
Image ID : LT05_115035_20040409
Google user : ndef
Folder name : rgee_backup
Date : 2023_06_03_15_35_15
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 0s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 5s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 10s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 15s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 20s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 25s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 30s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 35s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 40s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 45s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 50s>.
Polling for task <id: YHH2YOZSVEUEZPLCWN7AM2BE, time: 55s>.
State: COMPLETED
Moving image from Google Drive to Local ... Please wait Code
tmap mode set to interactive viewingstars object downsampled to 840 by 1189 cells. See tm_shape manual (argument raster.downsample)Variable(s) "NA" contains positive and negative values, so midpoint is set to 0. Set midpoint = NA to show the full spectrum of the color palette.4.2.2.2 무감독 분류(K-means)
Code
### 무감독
# Make the training dataset.
training <- aoi$sample(
region = geometry,
scale = 30,
numPixels = 100000
)
# Instantiate the clusterer and train it.
clusterer <- ee$Clusterer$wekaKMeans(9)$train(training)
# Cluster the input using the trained clusterer.
result <- aoi$cluster(clusterer)
# Display the clusters with random colors.
Map$centerObject(geometry)NOTE: Center obtained from the first element.4.2.3 RGEE 응용
4.2.3.1 Sentinel-2 자료를 활용한 산불피해지역 파악
대기보정이 완료된 유럽항공우주국 Sentinel-2 위성의 자료를 사용하여 산불 피해 지역을 분류해보았다.
다음은 자료를 확인하고 구득하는 코드이다.
Code
# 진짜 Danger zone
# 산불 피해 지역 분류
# SVM Classification using Sentinel-2 composite.
## AoI 폴리곤으로 지정 - rectangle vertices
geometry <- ee$Geometry$Polygon(
list(
c(128.9833, 37.65),
c(128.9833, 37.55),
c(129.1, 37.55),
c(129.1, 37.65)
)
)
#L2C 데이터(필터조건-범위:폴리곤, 시간: 산불직후)
image <- ee$ImageCollection("COPERNICUS/S2_SR")$
filterBounds(geometry)$
filterDate("2019-04-20","2019-04-30")$
first()$ #4월 20일 데이터만 뽑기
select(c(1,2,3,4,5,6,7,8,9,10,11))
# extract an image with the geometry mask
aoi <- image$clip(geometry)
# Display the result
Map$centerObject(geometry, zoom = 12)
Map$addLayer(
eeObject = aoi,
visParams = list(
bands = c("B4", "B3", "B2"),
min = 0,
max = 2^(12)
),
name = "Apr 2019 (True colours)"
) +
Map$addLayer(
eeObject = geometry
)Code
# Use these bands for prediction.
##all bands w/o atmosphiric detector
bands <- c("B2", "B3", "B4","B5","B6","B7", "B8","B11","B12")
# Manually created polygons.
## 수계 class - 0
water1 <- ee$Geometry$Rectangle(129.05, 37.64, 129.06, 37.63) # rectangle vertices
water2 <- ee$Geometry$Rectangle(128.984, 37.619, 128.988,37.618)
## 식생 class - 1
veget1 <- ee$Geometry$Rectangle(128.9837,37.6251, 128.986, 37.623)
veget2 <- ee$Geometry$Rectangle(129.05228,37.56383, 129.05833, 37.55921)
## 해빈 class - 2
beach1 <- ee$Geometry$Rectangle(129.07403, 37.60491, 129.07468, 37.60473)
beach2 <- ee$Geometry$Rectangle(129.0888, 37.59518, 129.08966,37.59469)
## 도시 class - 3
urban1 <- ee$Geometry$Rectangle(129.05612, 37.62045, 129.05897, 37.61923)
urban2 <- ee$Geometry$Rectangle(129.03256, 37.60757, 129.03406, 37.60702)
## 산불피해지역 class - 4
burnt1 <- ee$Geometry$Rectangle(129.04996, 37.60308, 129.05326, 37.59999)
burnt2 <- ee$Geometry$Rectangle(129.05876, 37.59954, 129.06502, 37.596280)
## 경작지 class - 5
crop1 <- ee$Geometry$Rectangle(129.02121, 37.61879, 129.02490, 37.61702)
crop2 <- ee$Geometry$Rectangle(129.08676, 37.58181, 129.09026, 37.57960)
# Make a FeatureCollection from the hand-made geometries.
polygons <- ee$FeatureCollection(c(
ee$Feature(water1, list(class = 0)),
ee$Feature(water2, list(class = 0)),
ee$Feature(veget1, list(class = 0)),
ee$Feature(veget2, list(class = 0)),
ee$Feature(beach1, list(class = 0)),
ee$Feature(beach2, list(class = 0)),
ee$Feature(urban1, list(class = 0)),
ee$Feature(urban2, list(class = 0)),
ee$Feature(burnt1, list(class = 1)),
ee$Feature(burnt2, list(class = 1)),
ee$Feature(crop1, list(class = 0)),
ee$Feature(crop2, list(class = 0))
))4.2.3.2 SVM Classifier(GEE 클라우드 컴퓨팅 환경)
Code
# Get the values for all pixels in each polygon in the training.
training <- aoi$sampleRegions(
# Get the sample from the polygons FeatureCollection.
collection = polygons,
# Keep this list of properties from the polygons.
properties = list("class"),
# Set the scale to get Landsat pixels in the polygons.
scale = 10
)
# Create an SVM classifier with custom parameters.
classifier = ee$Classifier$libsvm(
kernelType = "RBF"
)
# Train the classifier.
trained = classifier$train(training, "class", bands)
# Classify the image.
classified = aoi$classify(trained)
# Display the classification result and the input image.
## visual parameter
geoviz_image = list(bands = c("B8", "B4", "B3"),min = 0, max = 2^(12))
geoviz_class = list(min = 0, max = 1, palette = c("green","red"))
Map$centerObject(geometry, zoom = 12)
Map$addLayer(
eeObject = aoi,
visParams = geoviz_image,
name = "False color image"
) +
Map$addLayer(
eeObject = classified,
visParams = geoviz_class,
name = "Burned area"
) +
Map$addLayer(
eeObject = polygons,
name = "Training polygons"
)4.2.3.2.1 시각화
Code
# 로컬로 불러오기
{
ee_as_raster(
classified,
region = geometry$bounds(),
#dsn = NULL,
via = "drive",
#container = "rgee_backup",
scale = 30,
#maxPixels = 1e+09,
#lazy = FALSE,
#public = TRUE,
#add_metadata = TRUE,
#timePrefix = TRUE,
#quiet = FALSE,
#...
) %>% rast() -> rgee_svm
rgee_svm[rgee_svm==0]=NA
}- region parameters
sfg : POLYGON ((128.9833 37.55, 1 .... 3 37.65001, 128.9833 37.55))
CRS : GEOGCRS["WGS 84",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563, .....
geodesic : FALSE
evenOdd : TRUE
- download parameters (Google Drive)
Image ID : noid_image
Google user : ndef
Folder name : rgee_backup
Date : 2023_06_03_15_41_18
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 0s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 5s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 10s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 15s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 20s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 25s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 30s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 35s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 40s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 45s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 50s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 55s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 60s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 65s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 70s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 75s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 80s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 85s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 90s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 95s>.
Polling for task <id: M575XZML4GTJVNOXKKQPRFK5, time: 100s>.
State: COMPLETED
Moving image from Google Drive to Local ... Please wait 4.2.3.3 XGB Boosed Tree Classifier(Local 환경)
GEE로부터 로컬로 영상 불러오기
Code
- region parameters
sfg : POLYGON ((128.9833 37.55, 1 .... 3 37.65001, 128.9833 37.55))
CRS : GEOGCRS["WGS 84",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563, .....
geodesic : FALSE
evenOdd : TRUE
- download parameters (Google Drive)
Image ID : 20190420T020701_20190420T020656_T52SDG
Google user : ndef
Folder name : rgee_backup
Date : 2023_06_03_15_43_19
Polling for task <id: ECYPX3JWF37EZTEEU6E2QNGT, time: 0s>.
Polling for task <id: ECYPX3JWF37EZTEEU6E2QNGT, time: 5s>.
Polling for task <id: ECYPX3JWF37EZTEEU6E2QNGT, time: 10s>.
Polling for task <id: ECYPX3JWF37EZTEEU6E2QNGT, time: 15s>.
State: COMPLETED
Moving image from Google Drive to Local ... Please wait Tidymodel을 사용한 XGB 예측
Split dataset
Recipe
Modeling - Hyperparameter Tuning
Code
boost_tree() %>%
set_args( mtry = tune(),
trees = tune(),
min_n = tune(),
tree_depth = tune(),
learn_rate = tune(),
loss_reduction = tune(),
sample_size = tune(),
stop_iter = tune() ## step size
) %>%
set_engine("xgboost") %>%
set_mode("classification") -> gredbst
grid_latin_hypercube(
trees(),
tree_depth(),
min_n(),
loss_reduction(),
sample_size = sample_prop(),
finalize(mtry(), train_data),
learn_rate(),
stop_iter(),
size = 30
) -> gredbst_grid
gredbst_grid# A tibble: 30 × 8
trees tree_depth min_n loss_reduction sample_size mtry learn_rate stop_iter
<int> <int> <int> <dbl> <dbl> <int> <dbl> <int>
1 840 2 36 0.000000316 0.684 1 2.67e-10 11
2 1021 8 7 0.00000776 0.621 8 1.86e- 7 13
3 113 5 8 0.000000184 0.137 10 3.06e- 6 17
4 983 12 38 0.0000000677 0.128 11 4.97e- 4 9
5 1718 10 12 0.00000195 0.262 7 9.19e- 8 18
6 1928 3 25 0.957 0.806 11 5.47e- 5 17
7 1588 10 2 0.0281 0.530 5 2.82e- 7 9
8 601 3 21 0.407 0.650 8 7.62e- 3 15
9 1475 6 30 0.0000108 0.507 3 5.43e- 2 18
10 780 10 34 0.00102 0.988 3 5.20e- 6 10
# ℹ 20 more rowsCode
cls_wf <- workflow() %>%
add_recipe(wildfire_recipe,
#blueprint = hardhat::default_recipe_blueprint(allow_novel_levels = TRUE)
) %>%
add_model(gredbst, formula = ID ~ .)
####
{
all_cores <- parallel::detectCores(logical = F)
all_cores
comp_cluster <- parallel::makeCluster(all_cores - 2)
comp_cluster
#parallel::stopCluster(comp_cluster)
doParallel::registerDoParallel(comp_cluster)
}# 10-fold cross-validation
# A tibble: 10 × 2
splits id
<list> <chr>
1 <split [1228/137]> Fold01
2 <split [1228/137]> Fold02
3 <split [1228/137]> Fold03
4 <split [1228/137]> Fold04
5 <split [1228/137]> Fold05
6 <split [1229/136]> Fold06
7 <split [1229/136]> Fold07
8 <split [1229/136]> Fold08
9 <split [1229/136]> Fold09
10 <split [1229/136]> Fold10Code
# A tibble: 1 × 9
mtry trees min_n tree_depth learn_rate loss_reduction sample_size stop_iter
<int> <int> <int> <int> <dbl> <dbl> <dbl> <int>
1 6 1383 4 1 0.0432 0.0724 0.746 12
# ℹ 1 more variable: .config <chr>══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: boost_tree()
── Preprocessor ────────────────────────────────────────────────────────────────
0 Recipe Steps
── Model ───────────────────────────────────────────────────────────────────────
Boosted Tree Model Specification (classification)
Main Arguments:
mtry = 6
trees = 1383
min_n = 4
tree_depth = 1
learn_rate = 0.0432413337315338
loss_reduction = 0.0723561417184072
sample_size = 0.745668687273283
stop_iter = 12
Computational engine: xgboost Modeling - Fitting Model Using the Tuned Hyperparam
Code
Warning: package 'xgboost' was built under R version 4.2.3# A tibble: 4 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 accuracy binary 0.998 Preprocessor1_Model1
2 sens binary 0.998 Preprocessor1_Model1
3 spec binary 1 Preprocessor1_Model1
4 roc_auc binary 1.00 Preprocessor1_Model1레스터 표면 Prediction
Code
final_res %>% extract_fit_parsnip() %>%
terra::predict(outras) -> r_pred
vect_pred <- r_pred %>% unlist() %>% as.numeric() %>% -1 %>% as.vector() %>%
matrix(nrow=dim(outras)[1], dim(outras)[2], byrow = T) %>%
rast(crs=terra::crs(outras),
extent=terra::ext(outras))
vect_pred[vect_pred==0]=NA
tmap::tmap_mode("view")tmap mode set to interactive viewing4.2.3.4 DBSCAN(Local 환경)
밀도 기반 클러스터링
Code
시각화
11번 범주가 산불 지역인 것으로 보임.
모형 결과 비교
기존 Sentinel-2 영상의 방사해상도는 12-bit이며, 이에 따라 픽셀 값이 표현할 수 있는 범위는 0~4095로 보통 우리가 흔히 접할 수 있는 화면 출력 장치에 비하여 그 범위가 상당히 넓다. 저대비 영상이다.
Code

따라서 화면 출력 민감도 범위(e.g., 0~255)를 전부 사용하여 나타내려면 영상 강조 기법 중 하나인 Stretch를 사용하여 영상의 히스토그램을 변형할 필요가 있다.
따라서 시각화를 해주기 전 terra 패키지의 stretch 함수를 사용하여 선형 stretch를 수행하였다.
Code
dbscan_ras[dbscan_ras!=11]=NA
{
tm_shape(terra::stretch(outras, minv = 0, maxv = 255, minq = 0.2, maxq = 0.98)) +
tm_rgb(r = 3,
g = 2,
b = 1,
#max.value = 16280
) +
tm_shape(vect_pred)+
tm_raster(palette = c("red"),
title = "Predicted XGB(Local)") +
tm_shape(rgee_svm)+
tm_raster(palette = c("blue"),
title = "Predicted SVM(GEE)") +
tm_shape(dbscan_ras)+
tm_raster(title = "Predicted DBSCAN (Local)",
style = "cat",
palette = "cat")+
tm_shape(ee_as_sf(polygons)) +
tm_polygons(alpha = 0.7,
col = "class",
palette = "RdBu",
style = "cat")
}5 R에서 다른 프로그래밍 언어 사용하기
5.1 레이더 강수 자료 - Reticulate
레이더를 사용한 강수 추정 시 지형은 레이더의 신호를 막거나 교란하는 역할을 하며 특히 한반도는 산악지형 비중이 높아 많은 추정 오차를 야기한다. 예시로는 지형이 신호를 일부 혹은 전체를 막아 생기는 부분 빔 차폐(partial beam blockage)와 수신되는 반사도를 손실시켜 과소추정을 유발하는 것을 지형 클러터(ground clutter)가 있다. 하이브리드 고도면 강수추정기법(Hybrid Surface Rainfall Technique, HSR)은 관측고도가 가장 낮은 레이더 빈으로 구성된 고도각면 반사도만 강우장 마스크(rain field mask)로 사용하여 강우추정 정확도를 향상시키며 기존 CAPPI(Constant Altitude Plan Position Indicator) 대비 지형 또는 빔 차폐의 영향이 적다. 현재 기상청 날씨누리, 기상레이더 센터 홈페이지 등을 통하여 제공되는 레이더영상은 HSR 기법의 영상이다.

2019년부터 현재까지 기상청에서는 HSR 기법으로 도출한 반사도 자료를 매우 높은 시공간 해상도인 5분 간격, 500m \(\times\) 500m의 격자로 제공하고 있다. 이러한 자료의 속성에서 기인하는 여러 장점이 있는데, 강수 표면을 생성하기 위해 기존 관측소에서 관측한 강수량 자료에 대해서 내삽을 수행할 필요가 없으며, 5분 간격의 반사도로 제공되기 때문에 누적 강수량이 아닌 일정 기간 내 최대 강수도 구할 수 있다. 제공되는 레이더 반사도 인자 \(Z(mm^6m^{-3})\)를 강수강도 \(R(mm/hr)\)로 변환하려면 이에 관한 관계식인 Z-R 관계식(Z-R relationship)을 사용하여 변환을 해야 하며 다음과 같은 형태를 가진다.
\[
Z=\alpha R^\beta
\]
위 식에서 \(\alpha\)와 \(\beta\)는 경험적 상수이며 강수형태에 따라 달라진다. 기상청에서 통상적으로 제공하는 Z의 형태는 상용로그를 취한 dBZ 형태로 제공된다.
\[
Z\left(dBZ\right)=10\log\left(\frac{Z}{1mm^6m^{-3}}\right)
\]
여기서 Z의 단위로 나눔으로써 괄호 속의 값은 차원이 없는 수이며, 단위 부피 1m\(^3\) 내에 직경이 1mm인 물방울 1개를 한 단위로, 물방울이 10개 존재하면 10dBZ, 100개 존재하면 20dBZ이다.
자료의 속성정보는 기상청에서 다음과 같이 제공한다.


본 섹션에서는 기상청 기상자료개방포털에서 제공하는 산사태 발생 일시의 HSR 레이더 반사도를 Z-R 관계식을 통해 강수강도로 가공하였으며, 기상청에서 통계로 산출한 한국형 관계식의 모수인 \(\alpha=148, \ \ \beta=1.59\) 값을 적용하였다. 가공한 자료를 가지고 일 누적 강수량(mm/day)과 일 최대 강수량(mm/h)를 각각 도출한 과정을 담았다.
5.1.1 Time Series Data Wrangling using Numerical Python
일반 파이썬 환경은 use_python, Anaconda 환경은 use_condaenv,use_miniconda를 사용하여 파이썬 인터프리터 바이너리를 특정할 수 있다. 즉 어느 파이썬을 사용할지 특정 가능하다.
Code
+ "C:/Users/dydgn/AppData/Local/r-miniconda/condabin/conda.bat" "install" "--yes" "--name" "rgee" "-c" "conda-forge" "matplotlib"quarto와 같은 마크다운 문서의 경우 다음과 같이 코드 블록에 python이라는 옵션을 주어 파이썬 코드를 실행할 수 있다.

C:/Users/dydgn/AppData/Local/r-miniconda/envs/rgee/python.exe490C:\Users\dydgn\OneDrive - SNU\2023-1\lecture\SA3\TA\rgee사용자 정의 함수
Code
# Code Chunk of User Defined Functions
#### File IO
# zip pathfinder
def namezip(path):
# list to store files
res = []
# loop through directory
for file in os.listdir(path):
# check only zip files
if file.endswith('.zip'):
res.append(file)
return res
# simple zip finder
def findzip(path):
# list to store files
res = []
# loop through directory
for file in os.listdir(path):
# check only zip files
if file.endswith('.zip'):
join = os.path.join(path, file)
res.append(join)
return res
#### Data Handling
# Nested Compressed File Size viewer
def get_size_of_nested_compressed_file(filename):
#get the file size of bin file in mixed and nested compressed file
total_size = 0
# Check if the file is a .zip file
if zipfile.is_zipfile(filename):
with zipfile.ZipFile(filename, 'r') as zip_file:
# Get a list of all the files in the archive
archive_files = zip_file.namelist()
for archive_file in archive_files:
# Check if the file is a .gz file
if archive_file.endswith('.gz'):
with zip_file.open(archive_file, 'r') as gz_file:
# Read the entire compressed file into memory
compressed_data = io.BytesIO(gz_file.read())
compressed_data.seek(0)
# Get the size of the uncompressed file within the .gz archive
with gzip.GzipFile(fileobj=compressed_data, mode='rb') as uncompressed_file:
uncompressed_file.seek(0, os.SEEK_END)
uncompressed_size = uncompressed_file.tell()
total_size += uncompressed_size
# Check if the file is a .gz file
elif filename.endswith('.gz'):
with open(filename, 'rb') as gz_file:
# Read the entire compressed file into memory
compressed_data = io.BytesIO(gz_file.read())
compressed_data.seek(0)
# Get the size of the uncompressed file within the .gz archive
with gzip.GzipFile(fileobj=compressed_data, mode='rb') as uncompressed_file:
uncompressed_file.seek(0, os.SEEK_END)
uncompressed_size = uncompressed_file.tell()
total_size += uncompressed_size
# Otherwise, assume the file is a regular file and return its size
else:
total_size += os.path.getsize(filename)
return total_sizeCode
def hsr_min_mat_stacker(zipdir):
zplst = findzip(zipdir)
header_size = 1024
for i in range(len(zplst)):
total_size = get_size_of_nested_compressed_file(zplst[i])
#print("The total size of binary data file in '" + str(zplst[i]) + "' is {} bytes.".format(total_size))
#chk integrity
length = len(zipfile.ZipFile(zplst[i]).namelist())
if (total_size == 13282434*length):
pass
#print("The files are in full health")
# Check if the file size is non-zero
if total_size == 0:
pass
#print("The binary data file is empty.")
else:
# zip 파일 목록으로 루프
with zipfile.ZipFile(zplst[i], 'r') as zip_file:
# zip 파일 내부 목록으로 recursive 루프 돌리기
archive_files = zip_file.namelist()
for j in range(len(archive_files)):
# .gz인지 확인
if archive_files[j].endswith('.gz'):
with zip_file.open(archive_files[j], 'r') as gz_file:
# 메모리로 보내기
compressed_data = io.BytesIO(gz_file.read())
compressed_data.seek(0)
# 바이너리 형식 파일 읽어오기
with gzip.GzipFile(fileobj=compressed_data, mode='rb') as uncompressed_file:
uncompressed_file.seek(header_size)
file_content = uncompressed_file.read()
tmp = np.frombuffer(file_content, dtype=np.short)
uncompressed_file.close()
compressed_data.close()
# 5분 단위 영상 적층
if j!=0:
stack= np.append(stack,tmp)
#print("stack")
else:
stack = tmp
#print("1st loop")
# Scale factor
#define PUB_OUT -30000 //관측반경 밖
#define PUB_IN -25000 //관측영역 내 비관측영역
#define PUB_MIN -20000 //관측영역 내 표시를 위한 최소값
data = np.where(stack<-20000, 0, stack)
echo = data*0.01
# dBZ 수치를 강수강도로 변환환
R = dbz2rain(echo)
# 상용로그 형태 지수화 하여서 생긴 0 부분 0으로..
R[R<=0.04315743] = 0.0
gzcount = len(archive_files)
cube = R.reshape(gzcount,2881, 2305)
cube = np.flip(cube, 1)
cube = np.mean(cube, axis=0)
if i!=0:
res = np.vstack([res, cube[np.newaxis,...]])
else:
res = cube[np.newaxis,...]
return res
#### Data conversion
# converting dBZ to rain
def dbz2rain(x):
# Z-R Relation
ZRa = 148.
ZRb = 1.59
rain = (x*0.1 - np.log10(ZRa))/ZRb
rain = 10**rain
return rain
#### Plotting
def matplot(x):
plt.clf()
plt.imshow(x)
plt.colorbar()
plt.show()자료정제
Code

Reticulate의 최대 장점으로 R과 Python 간에 각 환경에서 지정한 변수를 다른 환경으로 가져올 수 있다. 예를 들어, Python에서 R로 가져올 시에는 R 코드 상에서 py$파이썬변수명을, Python 상에서 R 변수를 가져올 때에는 r.알변수명을 사용하면 된다.
다음은 Python 환경에서 도출한 최종 행렬을 R 환경에서 래스터 자료로 변환하는 과정이다.
Code
# 최대 강수 강도(mm/h)
r_rdr_19_1_max <- py$rdr_19_1_max %>%
raster(.,
xmn=(-1121*500),
xmx=((2305-1121)*500),
ymn=(-1681*500),
ymx=(2881-1681)*500,
crs = CRS("+proj=lcc +lat_1=30 +lat_2=60 +lat_0=38 +lon_0=126 +a=6378138.00 +b=6356752.314 +units=m +no_defs")
) %>% rast() %>%
project(crs(st_crs(roi)[[2]]),
threads = T)
# 24시간 누적 강수량 (mm)
r_rdr_19_1_accum <- py$rdr_19_1_accum %>%
raster(.,
xmn=(-1121*500),
xmx=((2305-1121)*500),
ymn=(-1681*500),
ymx=(2881-1681)*500,
crs = CRS("+proj=lcc +lat_1=30 +lat_2=60 +lat_0=38 +lon_0=126 +a=6378138.00 +b=6356752.314 +units=m +no_defs")
) %>% rast() %>%
project(crs(st_crs(roi)[[2]]),
threads = T) 결과 도시
2019년 10월 02일 강수자료
Code
r_rdr_19_1_accum[r_rdr_19_1_accum==0]=NA
r_rdr_19_1_max[r_rdr_19_1_max==0]=NA
{# 지도 한방에 그리기
tm_basemap(c("OpenStreetMap.HOT",
"https://mt1.google.com/vt/lyrs=y&hl=en&z={z}&x={x}&y={y}",
"https://mt1.google.com/vt/lyrs=s&hl=en&z={z}&x={x}&y={y}"),
group = c("OpenStreetMap.HOT",
"Google Satellite Imagery w/ label",
"Google Satellite Imagery wo/ label")) +
tm_shape(r_rdr_19_1_accum) +
tm_raster(n=10^5,
palette = "-Spectral",
style = "cont",
title = "강수량(mm/day)"
) +
tm_shape(r_rdr_19_1_max) +
tm_raster(n=10^5,
palette = "-Spectral",
style = "cont",
title = "최대 강수 강도(mm/h)"
) -> themap
tmap_leaflet(themap)|>
addMouseCoordinates()
}stars object downsampled to 898 by 1114 cells. See tm_shape manual (argument raster.downsample)
stars object downsampled to 898 by 1114 cells. See tm_shape manual (argument raster.downsample)Warning in is.na(group) && !is.null(names(server)): 'length(x) = 3 > 1' in
coercion to 'logical(1)'5.2 기타 언어
R은 파이썬 말고도 여러가지 언어와 같이 사용될 수 있으므로 참고. 본 섹션에서는 Fortran을 주로 살펴볼 예정.
Python과 R은 인터프리터 언어이므로 컴파일러 언어인 C/C++, Java, Fortran에 비해 매우 느리다. 따라서 빠른 연산을 요하는 R이나 Python의 경우에는 C/C++ 등의 빠른 속도의 런타임을 가진 언어로 래핑되어있다.
따라서 이러한 빠른 언어의 실행 속도를 맛 보는 시간을 갖고자 시도하였다.

R은 Fortran의 subroutine(사용자 정의 함수와 유사) 및 C의 사용자 정의 함수(user defined function)를 R환경으로 불러와서 사용할 수 있다.
사용하는 방법은 subruotine이나 사용자 지정 함수 파일을 동적 연결 라이브러리(Dinamic Link Library, .dll 파일)로 Build한 후 R 환경에 dyn.load("제작한.dll") 함수를 사용하여 불러온 후 .Fortran() 혹은 .C() 함수를 사용하여 적용할 수 있다.
코드 파일을 .dll 파일로 컴파일하여 사용하는 방법은 두 가지로 나뉜다.
본 실습지는 1번 방법을 사용하였다. 첫 번째 방법은 R 마크다운 문서(.Rmd) 혹은 Quarto(.qmd) 문서의 코드 청크 상단 중괄호에 fortran 혹은 c라고 명시하면 된다.
코드를 다 작성 후 해당 코드 블록 전체를 실행하면 자동으로 .dll 파일을 만들고 불러온다.
이후에 .Fortran 혹은 .C 함수를 사용하여 R로 불러오면 된다.
아래는 언어 간 자료형이 어떻게 교환되는지를 정리한 표이다.
참고로 해당방법으로 다른 언어의 함수를 가져올 시, 정수형은 8바이트 이상 자료형(c에서 signed long long int)에서 오류가 나는 것으로 보인다. 오버플로가 나지 않도록 주의.
| R | C | Fortran |
|---|---|---|
| integer | int * | integer |
| numeric | double * | double precision |
| – or – | float * | real |
| complex | Rcomplex * | double complex |
| logical | int * | integer |
| character | char * |
?.Fortran 참고 * |
| raw | unsigned char * | not allowed |
| list | SEXP * | not allowed |
| other | SEXP * | not allowed |
5.2.1 Fortran
포트란(Fortran, 이전 명칭 FORTRAN)은 1954년 IBM 704에서 과학적인 계산을 하기 위해 시작된 컴퓨터 프로그램 언어이다.
FORTRAN은 수식(Formula) 변환기(Translation)의 약자이다.(IBM Mathematical Formula Translating System에서 유래.)
포트란은 산술 기호(+, -, *, / 등)를 그대로 사용할 수 있으며, 삼각함수·지수함수·대수함수 등과 같은 기초적인 수학 함수들을 자연스럽게 불러내어 쓸 수 있으며, 과학계산에서 필수적인 벡터, 행렬계산기능 등이 내장되어 있는 과학 기술 전문언어이다.
포트란은 초대형 과학계산 문제의 프로그래밍에 필수적인 언어이며. 특히 자연과학이나 공학에서의 중요한 거대한 계산문제들을 슈퍼컴퓨터들을 이용하여 해결하는 데 있어서 C언어와 같이 범용프로그래밍 언어에 속하는 프로그래밍언어들에 비해 탁월한 효율이 있는 과학계산 전문 언어이다. 1990년대까지 널리 사용되어 왔던 FORTRAN 77에서 현재 Fortran 90/95, Fortran 2003, Fortran 2008등으로 계속 진보하고 있다.4
피보나치 수 계산
피보나치 수열(Fibonacci sequence)은 수학에서 다루는 수열이며 컴퓨터 알고리듬 강의에서 단골로 출현한다. 이 수열의 항들을 피보나치 수(Fibonacci number)라 부른다. 다음과 같은 점화식으로 피보나치 수열을 정의할 수 있다.
\[ F_0=0, \ \ F_1=1,\ \ \cdots, \ \ F_{n}=F_{n-1}+F_{n-2} \]
혹은 일반항으로…
\[ F_n = \frac{1}{2^{n-1}}\sum_{k=0}^{\lfloor \frac{n+1}{2} \rfloor} {n\choose2k+1}5^k \]
\(\lfloor \frac{n+1}{2} \rfloor\)는 \(\frac{n+1}{2}\) 이하의 최대 정수
\({n\choose2k+1}\)는 조합
피보나치 수열은 재귀함수와 동적 계획법(dynamic programing)으로 구현가능하다. 본 예시는 동적 계획법을 사용하였다.
Code
! 간단한 포트란 서브루틴
! 피보나치 수 계산기
! n을 받아 f를 리턴
subroutine fibonacci(n,f)
! 변수 선언부
implicit none
integer :: f, i, n, fortn
integer, dimension(n+1) :: a
!포트란 인덱스 번호는 1부터
fortn=n+1
!다이나믹 프로그래밍
a(1) = 0
a(2) = 1
if(n>1)then
do i = 3, fortn
a(i) = a(i - 1) + a(i - 2)
end do
end if
! 피보나치 수열의 마지막
f = a(fortn)
!f값 리턴
return
end subroutine fibonaccigfortran -fno-optimize-sibling-calls -O2 -mfpmath=sse -msse2 -mstackrealign -c f9588b816de54a.f95 -o f9588b816de54a.o
gcc -shared -s -static-libgcc -o f9588b816de54a.dll tmp.def f9588b816de54a.o -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib/x64 -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib -lgfortran -lm -lquadmath -LC:/R/R-42~1.2/bin/x64 -lR위 코드 블록을 실행하면 f95로 시작하면서 확장자가 .dll인 파일이 작업 디렉터리에 생긴다.
knitr을 통해서 빌드한 경우에는 dyn.load("제작한.dll")를 통해 불러오지 않고도 다음과 같이 바로 R환경으로 불러올 수 있다.
입력되는 \(n\) 값이 4바이트 정수 범위(-32,768 ~ 32,767) 안에 있도록 할 것.
Code
# 포트란 함수를 R 사용자 함수로 래핑
fortran_fibo <- function(x){
res <- .Fortran("fibonacci",
n= as.integer(x),
f = 0L)
return(res$f)
}
fibo <- array()
for (i in 0:19) {
fibo[i+1] <- fortran_fibo(i)
}
f_n <- array(0:19)
# https://en.wikipedia.org/wiki/Fibonacci_sequence <- 정답은 여기에
cbind(f_n,fibo) |>
as.data.frame() |>
reactable()R 코드와 속도 비교를 위해 동일한 알고리듬으로 작성한 피보나치 수 계산 함수를 R에서도 사용자 정의 함수로 구현하였다.
결과는 포트란 버전과 동일하다.
Code
속도를 비교하였다. \(F_{19}\)를 계산하는 함수에서 Fortran이 R보다 평균적으로 약 3배 정도 빠름을 볼 수 있다.
Code
Unit: milliseconds
expr min lq mean median uq max neval cld
Fortran 0.0006 0.0006 0.001163 0.0007 7e-04 0.0382 100 a
R 0.0016 0.0017 0.002026 0.0019 2e-03 0.0174 100 b
Estimating the value of Pi using Monte Carlo
몬테카를로 시뮬레이션(Monte Carlo simulation)은 확률과 통계학에서 사용되는 방법 중 하나로, 확률 분포를 이용하여 난수를 발생시켜 실험을 수행하고, 이를 통해 원하는 결과를 예측하는 방법이다.
원주율(\(\pi\))을 구하는 방법 중 하나가 바로 몬테카를로 시뮬레이션이며, 이 방법은 원주율과 사각형의 넓이와 원의 넓이의 비율을 이용하여 원주율을 계산한다.

자세한 내용은 다음과 같다.
- 크기가 1인 정사각형을 그리고, 정사각형의 중심에 원을 그린다.
- 0과 1 사이의 난수를 무작위로 생성하여, 이를 정사각형 안에 무작위로 찍어서 원 안에 들어가는 점의 수를 계산한다.
- 가로 세로 길이가
1인 사각형을 생각할 것
- 가로 세로 길이가
- 원의 넓이와 정사각형의 넓이의 비율을 계산한 값은 원주율의 근사치이다.
\[ \frac{\text{area of the circle}}{\text{area of the square}} = \frac{\pi r^2}{4} \]
\[ \frac{\pi}{4} = \frac{\# \text{ of pts generated inside the circle}}{\# \text{ of pts generated inside the square(total)}} \]
\[ \pi = 4 \times \frac{\# \text{ of pts in the circle}}{\# \text{ of all generated pts}} \]
이 방법을 여러 번 반복하여 점의 수를 늘릴수록 원주율을 더욱 정확하게 근사할 수 있다.
하지만, 반복문을 사용하는 시뮬레이션의 특성 상 시행의 수가 증가할 수록 결과 도출 속도가 느려지기 마련이다. 이럴 때 Fortran과 같이 빠른 언어를 사용한다면 시간을 단축시킬 수 있다.
다음은 위 설명을 코드로 옮긴 것이다.
Code
subroutine montepi(N,P)
implicit none
integer :: N,L,NUM_P_CIRCLE,NUM_P_TOTAL
real*8 :: D,P
real*8, dimension(2) :: COORD
! initialization
NUM_P_CIRCLE=0
NUM_P_TOTAL=0
! nth simulations
DO L=1,N
! Call the function that returns random numbers
CALL RANDOM_NUMBER(COORD)
! Distance calculation
D=(COORD(1)**2)+(COORD(2)**2)
! If a certain point is located inside the radious
! then count
IF(D<=1)NUM_P_CIRCLE=NUM_P_CIRCLE+1
! count the total
NUM_P_TOTAL=NUM_P_TOTAL+1
ENDDO
!
P = 4.* NUM_P_CIRCLE/NUM_P_TOTAL
return
end subroutine montepigfortran -fno-optimize-sibling-calls -O2 -mfpmath=sse -msse2 -mstackrealign -c f9588b86ce83bca.f95 -o f9588b86ce83bca.o
gcc -shared -s -static-libgcc -o f9588b86ce83bca.dll tmp.def f9588b86ce83bca.o -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib/x64 -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib -lgfortran -lm -lquadmath -LC:/R/R-42~1.2/bin/x64 -lRCode
[1] 3.141624마찬가지로 R로도 동일하게 만들었다.
Code
[1] 3.145속도를 비교하면 꽤나 많은 차이를 보임을 알 수 있다. 눈금이 로그 스케일임을 감안하자.
Code
Unit: milliseconds
expr min lq mean median uq max neval cld
Fortran 1.5216 1.5528 1.62935 1.59095 1.6217 3.2135 50 a
R 65.8380 81.6008 82.00824 82.57570 83.8676 87.1223 50 b
Taylor 급수를 사용한 Sine 함수 근사
미적분학에서 다루는 Taylor 급수(Taylor series)는 함수를 무한항급수의 형태로 나타낼 수 있는 방법 중 하나다. 특정 점에서의 함수값과 그 함수의 \(n\)차 도함수 값들이 주어졌을 때, 그 함수를 그 주변에서 다음과 같이 무한항급수의 형태로 근사할 수 있다.
\[ f(x)= f(a)+(x-a)f^\prime(a)+\frac{(x-a)^2}{2!}f^{\prime\prime}(a)+\frac{(x-a)^3}{3!}f^{\prime\prime\prime}(a)+\cdots \]
혹은
\[ f(x) = \sum_{k=0}^{\infty}\frac{(x-a)^k}{k!}f^{(k)}(a) \]
이 때, \(a=0\)일 때 Maclaurin 급수라고 한다. 삼각함수를 다항함수로 근사시킬 때 바로 이를 사용한다.
사인함수를 \(n\)번 미분하면 다음과 같이 반복되는 주기를 갖는다.
\[ \begin{gather*} \sin(x)= \sin(x) \\ \sin^{\prime}(x)= \cos(x)\\ \sin^{\prime\prime}(x)= -\sin(x) \\ \sin^{\prime\prime\prime}(x)= -\cos(x) \\ \sin^{\prime\prime\prime\prime}(x)= \sin(x) \\ \vdots \end{gather*} \]
앞서 살펴본 테일러 급수 전개를 사인 함수에 적용시키면 다음과 같다.
\[ \sin(x) = \sin(a)+(x-a)\cos(a)-\frac{(x-a)^2}{2!}\sin(a) -\frac{(x-a)^3}{3!}\cos(a)+\frac{(x-a)^4}{4!}\sin(a)+\cdots \]
여기서 \(\sin(0)\)은 0이므로, 미분하여 \(\sin\) 항들은 소거할 수 있다.
\[ \begin{gather*} \sin(0)= 0 \\ \sin^{\prime}(0)= 1\\ \sin^{\prime\prime}(0)= 0 \\ \sin^{\prime\prime\prime}(0)= -1 \\ \sin^{\prime\prime\prime\prime}(0)= 0 \\ \vdots \end{gather*} \]
이를 이용하여 테일러 급수의 \(a=0\)일 때인 Maclaurin 급수를 사용하여 다음과 같이 나타낼 수 있다.
\[ \sin(x) = x - \frac{x^3}{3!}+\frac{x^5}{5!}-\frac{x^7}{7!}+\cdots \]
혹은
\[ \sin (x) = \sum_{k=0}^{\infty}-1^k \cdot \frac{x^{(2k+1)}}{(2k+1)!} \]
다음은 위에서 살펴본 근사항들을 직접 코드로 적용시켜보았다.
먼저 포트란 코드이다. Maclaurin 급수의 항들을 구현 시 많은 계산을 요하는 팩토리얼을 사용하지 않고, n-1번째 항이 n번째 항의 부분합이라는 성질을 이용하였다(term = -term * angle * angle / ((2*i)*(2*i+1))).
Code
! 삼각함수 테일러 근사
! 1001개 급수 항
subroutine sine(angle,result)
! 변수 선언부
implicit none
integer::i
real*8::angle,result,term,twoPI
! wrap the angle into 2pi cycle
twoPI = 2. * 3.141592865358979
angle = angle - twoPI * floor( angle / twoPI )
! first term of taylor series
term = angle
result = term
! 1+ith taylor series
do i=1,1000
term = -term * angle * angle / ((2*i)*(2*i+1))
result = result + term
end do
!리턴리턴
return
end subroutine sinegfortran -fno-optimize-sibling-calls -O2 -mfpmath=sse -msse2 -mstackrealign -c f9588b82a2271e4.f95 -o f9588b82a2271e4.o
gcc -shared -s -static-libgcc -o f9588b82a2271e4.dll tmp.def f9588b82a2271e4.o -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib/x64 -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib -lgfortran -lm -lquadmath -LC:/R/R-42~1.2/bin/x64 -lR위 함수를 R 함수로 래핑하였다.
Code
# 포트란 함수를 R 사용자 함수로 래핑
fortran_sine <- function(x){
res <- .Fortran("sine",
angle= x*1.,
result = 0.)
return(res$result)
}
tibble(x=seq(-10,10,0.1)) %>%
mutate(`Taylor Approx. Sine Function(Fortran)`= map(x,fortran_sine)%>%unlist() ) %>%
mutate(`R Built-in Sine Function` = sin(x)) %>%
pivot_longer(-x) %>%
ggplot(aes(x,value))+
geom_path()+
facet_wrap(~name)
R의 내장함수와 동일함을 볼 수 있다. 다음은 R에 상응하는 코드이다.
Code
r_sine <- function(angle){
twoPI <- 2.0 * 3.141592865358979
angle <- angle - twoPI * floor( angle / twoPI )
term <- angle
result <- term
for (i in 1:1000) {
term <- -term * angle * angle / ((2*i)*(2*i+1))
result <- result + term
}
return(result)
}
ggplot(data.frame(x=0), aes(x)) +
geom_function(fun = sin,
data = data.frame(x = -10:10,
fun_name = "R Built-in Sine Function")
) +
geom_function(fun = r_sine,
data = data.frame(x = -10:10,
fun_name = "Taylor Approx. Sine Function(R)")
) +
facet_wrap(~fun_name)
Code
Warning in microbenchmark(Fortran = fortran_sine(2), R = r_sine(2), `R
Built-in` = sin(2), : Could not measure a positive execution time for 5
evaluations.Unit: nanoseconds
expr min lq mean median uq max neval cld
Fortran 5400 5600 6007.72 5800 5900 127300 10000 a
R 33200 35300 37231.66 36500 37700 238800 10000 b
R Built-in 0 0 37.27 0 0 17500 10000 c
5.2.2 C, C++
C/C++는 잘 몰라요 ㅜㅜ
사실 맘편하게 Rcpp 패키지를 사용하는게 100배 나은 것 같슴돠
25 Rewriting R code in C++ | Advanced R (hadley.nz)
그래도 예시는 남겨둘게요!
gcc -I"C:/R/R-42~1.2/include" -DNDEBUG -I"C:/R/rtools42//x86_64-w64-mingw32.static.posix/include" -O2 -Wall -std=gnu99 -mfpmath=sse -msse2 -mstackrealign -c c88b856246adc.c -o c88b856246adc.o
gcc -shared -s -static-libgcc -o c88b856246adc.dll tmp.def c88b856246adc.o -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib/x64 -LC:/R/rtools42//x86_64-w64-mingw32.static.posix/lib -LC:/R/R-42~1.2/bin/x64 -lRTest the square() function:
Footnotes
-
All readr functions yield strings encoded in UTF-8. This encoding is the most likely to give good results in the widest variety of settings. By default, readr assumes that your input is also in UTF-8. This is less likely to be the case, especially when you’re working with older datasets.
-
A feature is thought of as a thing, or an object in the real world, such as a building or a tree. As is the case with objects, they often consist of other objects. This is the case with features too: a set of features can form a single feature. A forest stand can be a feature, a forest can be a feature, a city can be a feature. A satellite image pixel can be a feature, a complete image can be a feature too.
Features have a geometry describing where on Earth the feature is located, and they have attributes, which describe other properties. The geometry of a tree can be the delineation of its crown, of its stem, or the point indicating its centre. Other properties may include its height, color, diameter at breast height at a particular date, and so on.
실제 지구를 수학적으로 근사화시킨 회전 타원체. 통상, 회전축을 기준으로 회전하는 기하학적 타원체로써, 굴곡이 없는 매끈한 면으로 가정됨↩︎